一、集群搭建
1、前置环境
(1)virtual memory
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]elasticsearch用户拥有的内存权限太小,至少需要262144
- 执行命令
vim /etc/sysctl.conf - 添加如下内容
vm.max_map_count=262144 - 保存退出,刷新配置文件
sysctl -p
(2)file descriptors
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]elasticsearch用户拥有的可创建文件描述的权限太低,至少需要65536
vim /etc/security/limits.conf在最后添加
* soft nofile 65536
* hard nofile 65536重新登录即可生效,可使用命令查看是否生效
ulimit -H -n2、生成认证证书文件
(1)生成CA证书
先下载 es 安装包,或者先启动一个容器,执行 bin 目录下的脚本工具
执行以下命令生成CA证书
./bin/elasticsearch-certutil ca第一个输入为生成的文件名,默认即可
第二个输入为证书密码,置空,不要输入密码,否则后续无法启动
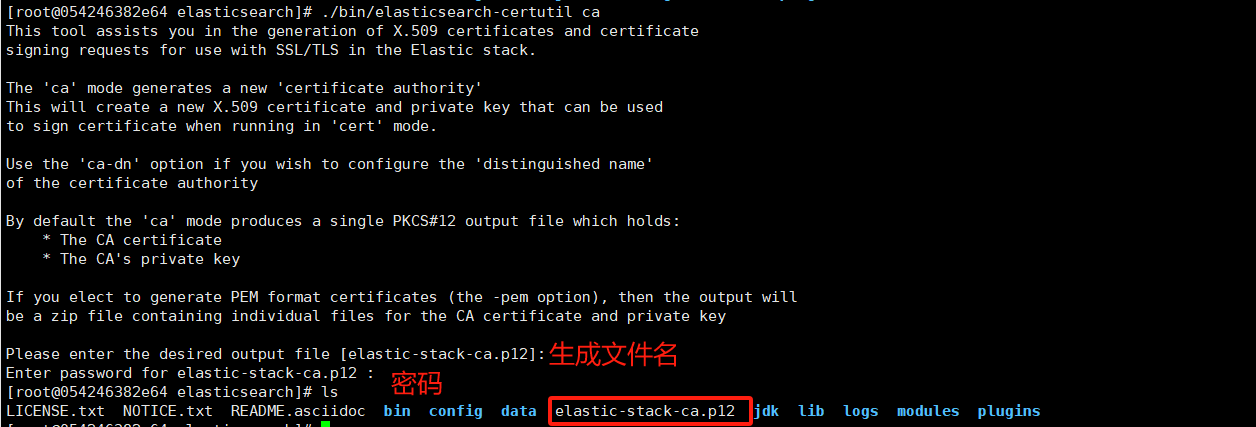
执行后,在es根目录生成 elastic-stack-ca.p12 文件
(2)生成秘钥
使用第一步生成的证书,产生p12密钥
./bin/elasticsearch-certutil cert --ca elastic-stack-ca.p12- 第一个输入为上面的 CA 证书密码
- 第二个输入为秘钥文件名,默认即可
- 第三个输入为秘钥文件密码,置空,不要输入密码,否则后续无法启动
Enter password for CA (elastic-stack-ca.p12) :
Please enter the desired output file [elastic-certificates.p12]:
Enter password for elastic-certificates.p12 :执行后,在es根目录生成 elastic-certificates.p12 文件
之后将两个文件拷贝到所有节点的 es根目录/config/certs/ 目录下
赋予权限,至少要给可读权限
chmod 744 elastic-certificates.p12
chmod 744 elastic-stack-ca.p123、配置文件
集群模式搭建配置文件 elasticsearch.yml
####################### 基本配置 ############################
# ip地址.
network.host: 0.0.0.0
# 端口(默认,可缺省)
http.port: 9200
# 内部节点之间沟通端口(默认,可缺省)
transport.tcp.port: 9300
# 数据和存储路径
#path.data: /opt/data
#path.logs: /opt/logs
####################### 集群配置 ############################
# 集群名称,集群内部保持一致,保证唯一
cluster.name: cluster-1
# 节点名称,必须不一样
node.name: node-1
# 是否候选主节点(有资格成为主节点?)
node.master: true
# 是否存储数据
node.data: true
# 最大集群节点数
#node.max_local_storage_nodes: 3
# es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["localhost:9300","节点2IP:9300","节点3IP:9300"]
# es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
####################### 密码认证 ############################
# 密码认证
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization
xpack.security.enabled: true
xpack.license.self_generated.type: basic
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: certs/elastic-certificates.p12
####################### 快照 ############################
# 如需使用快照,需要配置存储库
path.repo: ["/usr/share/elasticsearch/snapshot"]
# 如果是CentOS 6版本 加入以下两行
#bootstrap.memory_lock: false
#bootstrap.system_call_filter: false3、jvm参数
可设置 jvm 参数
vi ./elasticsearch/config/jvm.options默认情况下,ES启动JVM最小内存1G,最大内存1G
-Xms1g
-Xmx1g4、启动集群
(1)docker
拉取镜像
docker pull elasticsearch:7.8.0启动镜像(提前创建挂载文件,并赋予权限)
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.8.0(2)原生启动
下载
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.8.0-linux-x86_64.tar.gz
# 或华为镜像站中下载
https://mirrors.huaweicloud.com/elasticsearch/解压
tar -zxvf elasticsearch-7.6.2-linux-x86_64.tar.gz因为安全问题elasticsearch 不让用root用户直接运行,所以要创建新用户
useradd elk
passwd elk再输入两次密码(8位)
chown -R elk:elk /usr/local/elasticsearch切换用户,启动
su elk
cd /usr/local/elasticsearch
bin/elasticsearch &5、设置密码
只需要在其中一个节点执行,即可将密码同步到其他节点
如果是docker方式,则需要进入容器
docker exec -it 容器id /bin/bash设置密码
bin/elasticsearch-setup-passwords interactive这里会设置六个账号的密码:elastic,apm_system,kibana,logstash_system,beats_system,remote_monitoring_user
Changed password for user [apm_system]
Changed password for user [kibana_system]
Changed password for user [kibana]
Changed password for user [logstash_system]
Changed password for user [beats_system]
Changed password for user [remote_monitoring_user]
Changed password for user [elastic]elastic 这个是 es 登录的用户名
修改密码
es修改密码在安装es的机器上,执行命令如下:(将密码设置为:12456)
curl -H "Content-Type:application/json" -XPOST -u elastic 'http://127.0.0.1:9200/_xpack/security/user/elastic/_password' -d '{ "password" : "123456" }'这个时候会提示:需要你输入老密码,输入老密码之后,然后回车
校验设置的新密码是否有问题:(输入你的新密码)
curl -u elastic 'http://ip:9200/_xpack/security/_authenticate?pretty'访问http://ip:9200,需要输入账号密码才可以访问
访问方式
因为在es的配置文件中,选用的加密方式为basic,所以我们也可以对用户名密码进行手动加密,访问https://www.base64encode.org/地址,在输入框中输入 elastic:123456,进行加密,并在头部加上“Basic ”字符串就是最终的Authorization的值了,该值与第一种方式获取的是一致的。
curl localhost:9200 --user elastic:123456或
curl -X GET "localhost:9200/_snapshot?pretty" --user elastic:123456pretty:美化 json 输出--user elastic:Rewind_922:认证
6、查看集群健康
除了配置文件需要修改,其他的和单机安装es一样
安装完成之后,访问下面路径,可查看集群状态,如果返回的 node.total 是3,代表集群搭建成功
curl http://127.0.0.1:9200/_cat/health?v --user elastic:123456二、数据迁移
1、reindex
Reindex会将一个索引的数据复制到另一个已存在的索引,但是并不会复制原索引的mapping(映射)、shard(分片)、replicas(副本)等配置信息。
- 重建是创建新索引,原有索引保留
- 原有索引_source必须开启,否则找不到原始数据
-
_reindex会将一个索引的快照数据copy到另一个索引,默认情况下存在相同的_id会进行覆盖(一般不会发生,除非是将两个索引的数据copy到一个索引中) - 索引重建建议,严格业务场景,目标索引mapping结构建议先创建好,不使用es动态推测字段类型的方式。
(1)需求背景
ES版本兼容性
- 同一大版本范围内升级,索引读写兼容
- 不同大版本升级,索引读写不兼容,需要重建索引
集群索引迁移
- 集群迁移,索引服务不停机,数据提前迁移
分片数量变更
- 原有分片数量太少,重建变多
- 原有分片数量太多,重建变少
- ES索引分片,一旦创建,原索引是不能修改分片数量的
文档结构变更
- 字段类型变更,已有索引字段类型是不可以修改的
- 字段属性变更,历史数据的字段属性是不会刷新的
- 文档对象结构变更
(2)基本命令解读
POST_reindex
{
"source": {
"index": "原始索引"
},
"dest": {
"index": "新目标索引"
}
}URL参数
refresh:目标索引是否立即刷新waif_for_active_shards:重建索引分片响应设置Scroll:快照查询时间slicing:重建并行任务切片Max_docs:单次最大数据量,条数requests_per_second:单次执行的重建文档数据量
请求参数
confilicts:索引数据冲突如何解决,直接覆盖还是中断source:原索引配置信息dest:新索引配置信息script:脚本处理,修改原索引信息后再写入新索引
返回参数
{
"took" : 639, // 执行全过程使用的毫秒数
"updated": 0, // 成功修改的条数
"created": 123, // 成功创建的条数
"batches": 1, // 批处理的个数
"version_conflicts": 2, // 版本冲突个数
"retries": { // 重试机制
"bulk": 0, // 重试的批个数
"search": 0 // 重试的查询个数
}
"throttled_millis": 0, // 由于设置requests_per_second参数而sleep的毫秒数
"failures" : [ ] // 失败的数据
}
(3)冲突解决
version_type 属性默认值为 internal,即当发生冲突后会覆盖之前的 document,而当设置为external则会新生成一个另外的 document,设置方式如下:
POST _reindex
{
"source": {
"index": "my_index_name"
},
"dest": {
"index": "my_index_name_new",
"version_type": "external"
}
}
将 op_type 设置为 create 时,只会对发生不同的 document 进行 reindex,(若定时机制的 reindex则可以使用该方式只对最新的不存在的 document 进行 reindex)。并且可以将 conflicts 属性设置为proceed,将冲突进行类似于 continue的操作,设置方式如下:
POST _reindex
{
"conflicts": "proceed",
"source": {
"index": "my_index_name"
},
"dest": {
"index": "my_index_name_new",
"op_type": "create"
}
}(4)条件限制
对满足 query 条件的数据进行 reindex 操作,查询方式如下:
POST _reindex
{
"source": {
"index": "my_index_name",
"type": "my_type_name",
"query": { // query的条件
"term": {
"user": "user_value"
}
}
},
"dest": {
"index": "my_index_name_new"
}
} (5)多Index、Type数据的reindex
可以将多个索引或类型的数据reindex到一个新的索引中,当然还可以使用query查询条件只对其中满足条件的部分数据进行reindx,若不设置冲突则还是默认会进行覆盖,只是不能保证相同ID的数据那个索引的数据会被先索引而被覆盖,设置方式如下:
POST _reindex
{
"source": {
"index": [
"index_name_1",
"index_name_1"
],
"type": [
"type_name_1",
"type_name_2"
],
"query": {//query的条件
"term": {
"user": "kimchy"
}
}
},
"dest": {
"index": "all_together_index_name"
}
}(6)条数和排序控制
POST _reindex
{
"size": 10000, // 值reindex按照sort排序后的size条数据
"source": {
"index": "my_index_name",
"sort": { "date": "desc" } //排序
},
"dest": {
"index": "my_index_name_new"
}
}(7)限制重建索引数据字段
原有数据字段过多,需要限制筛选部分进行重建
满足_source中包含数组field(字段)的数据才会被reindex,设置方式如下:
POST_reindex
{
"source": {
"index": "my-index-000001",
"_source": ["user.id", "_doc"]
},
"dest": {
"index": "my-new-index-000001"
}
}(8)字段重命名
- 原有的数据字段名称不合理,重新按照新字段命名
- 基于脚本机制修改
- ES字段名称原始是不允许修改的,但通过脚本可以操作
POST _reindex
{
"source": {
"index": "test"
},
"dest": {
"index": "test2"
},
"script": {
"source": "ctx._source.tag = ctx._source.remove(\"flag\")"
}
}(9)远程 reindex
可以将远程(其他集群)的数据 reindex 到当前的集群环境中,但是需要设置当前集群的elsticsearch.yml配置中设置远程白名单列表,配置 reindex.remote.whitelist 属性,如otherhost:9200, another:9200, 127.0.10.*:9200, localhost:* 。只要环境可访问,则可以在任何版本之间对数据进行reindex,那么这也是版本es升级的数据迁移不错的选择。为了使发送到旧版本的弹性搜索的查询,查询参数被直接发送到远程主机,而不需要进行验证或修改。
但是manual 和 automatic slicing.不能使用远程reindex,设置方式如下:
reindex:
remote:
whitelist: "otherhost:9200, another:9200, 127.0.10.*:9200, localhost:*"POST _reindex
{
"source": {
"remote": {
"host": "http://otherhost:9200", // 远程es的ip和port列表
"socket_timeout": "1m",
"connect_timeout": "10s", // 超时时间设置
"username": "用户名",
"password": "密码"
},
"index": "my_index_name", // 源索引名称
"query": { // 满足条件的数据
"match": {
"test": "data"
}
}
},
"dest": {
"index": "dest_index_name" // 目标索引名称
}
}2、fs快照
(1)描述
ES提供快照和恢复功能,我们可以在远程文件系统仓库(比如共享文件系统、S3、HDFS等)中单独给部分索引或者整个集群创建快照。这些快照对备份非常有用,它们能相对较快地被恢复。但是,快照只能被恢复到可以读取他们的ES版本中:
在5.x创建的索引的快照可以被恢复到6.x;
在2.x创建的索引的快照可以被恢复到5.x;
在1.x创建的索引的快照可以被恢复到2.x;
(2)配置存储路径
在 elasticsearch.yml 配置一下内容,作为快照存储路径,重启Elasticsearch
path.repo: ["/home/elk/backup"]由于es都是使用的非root用户启动,当前用户需要有权限能读写,所以建议目录设置为用户/home/{user}/backup,或者配置到其他路径,并设置为elk用户的管理权限
首先需要在数据源ES节点服务器上创建仓库,并且要设置这个目录是共享的目录,所有的节点都能对这个目录进行读写。比如搭建 NFS 文件共享。
(3)注册快照仓库
执行http 注册存储库
curl -X PUT "localhost:9200/_snapshot/仓库名" -H 'Content-Type: application/json' -d'
{
"type":"fs",
"settings":{
"location":"/usr/share/elasticsearch/snapshot/repo1",
"compress":true,
"chunk_size":null,
"max_restore_bytes_per_sec":"40mb",
"max_snapshot_bytes_per_sec":"40mb",
"readonly":false
}
}type:快照类型location:存储库路径(必填,其余可缺省)compress:是否压缩
(4)查询快照仓库
- 查询已注册仓库列表
curl -X GET "localhost:9200/_snapshot"返回
{
"backup230920":{
"type":"fs",
"settings":{
"chunk_size":null,
"location":"/usr/share/elasticsearch/snapshot/backup230920",
"max_restore_bytes_per_sec":"40mb",
"readonly":"false",
"compress":"true",
"max_snapshot_bytes_per_sec":"40mb"
}
},
"repo1":{
"type":"fs",
"settings":{
"chunk_size":null,
"location":"/usr/share/elasticsearch/snapshot/repo1",
"max_restore_bytes_per_sec":"40mb",
"readonly":"false",
"compress":"true",
"max_snapshot_bytes_per_sec":"40mb"
}
}
}- 查询指定仓库
curl -X GET "localhost:9200/_snapshot/repo*,*backup*"可以使用逗号间隔多个仓库,星号通配符匹配仓库名字,上面示例返回仓库名以repo开头的和包含backup的仓库信息
(5)创建快照
一个仓库可以拥有同一个集群的多个快照。在一个集群中快照拥有一个唯一名字作为标识。在仓库 my_backup 中创建名字为 snapshot_1 的快照,可以通过执行下面的命令来实现:
curl -X PUT "localhost:9200/_snapshot/my_backup/snapshot_1?wait_for_completion=true"参数 wait_for_completion 决定请求是在快照初始化后立即返回(默认),还是等快照创建完成之后再返回。快照初始化时,所有之前的快照信息会被加载到内存,所以在一个大的仓库中改请求需要若干秒(甚至分钟)才能返回,即使参数 wait_for_completion 的值设置为 false。
默认情况下,创建一个快照会包含集群中所有打开和启动状态的索引。可以通过在创建快照的请求体中定义索引列表来改变这个默认处理:
curl -X PUT "localhost:9200/_snapshot/my_backup/snapshot_2?wait_for_completion=true" -H 'Content-Type: application/json' -d'
{
"indices": "index_1,index_2",
"ignore_unavailable": true,
"include_global_state": false
}要包含到快照中索引列表可以使用支持多个索引语法的 indices 参数来指定。快照请求也支持 ignore_unavailable 选项,该选项设置为 true 时,在创建快照时会忽略不存在的索引。默认情况下,如果选项 ignore_unavailable 没有设值,一个索引缺失,快照请求会失败。
通过设置 include_global_state 为 false,可以阻止集群全局状态信息被保存为快照的一部分。默认情况下,如果如果一个快照中的一个或者多个索引没有所有主分片可用,整个快照创建会失败,该情况可以通过设置 partial 为 true 来改变。
快照名可以通过使用 date_math_expressions 来自动获得,和创建新索引时类似。注意特殊字符需要 URI 转码处理。
例如,在名字中使用当前日期,比如 snapshot-2018.05.11,来创建快照,可以使用如下命令完成:
PUT /_snapshot/my_backup/<snapshot-{now/d}>
curl -X PUT "localhost:9200/_snapshot/my_backup/%3Csnapshot-%7Bnow%2Fd%7D%3E"索引的快照过程是增量的。在创建索引快照的过程中,ElasticSearch会分析仓库中已经存在的索引文件,只拷贝那些在最后一次快照之后被创建或者更新的文件。快照过程以非阻塞的方式执行,所有的索引和搜索操作都可以对正在被创建快照的索引继续执行。一个快照表示的是这个索引在快照被创建时间点的索引视图,所以在索引过程开始之后被添加到索引中的记录不会出现在快照中。快照过程会立即在已经启动的主分片上开始并且不会在此时重新定位。在版本 1.2.0 以前,如果共同快照中的索引在集群中发生任何重新定位或者初始化,快照操作将失败,从 1.2.0 版本开始,ElasticSearch 会等重新定位或者初始化主分片完成之后再进行快照操作。
除了创建每个索引的备份,快照过程也能存储全局集群元数据,包括持久化的集群设置和模版。临时设置和注册的快照仓库不会存储为快照的一部分。
任何时候,在集群中只能有一个快照过程被执行。当创建一个特定分片的快照时,该分片不能移动到另一个节点,这会干扰(interfere with)平衡进程和分配过滤(allocation filtering)。ElasticSearch 一旦在快照完成之后才能移动分片到其他节点。
(6)查看快照
- 查看指定快照
支持通配符,支持多个
curl -X GET "localhost:9200/_snapshot/my_repo1/snapshot_*,some_other_snapshot"- 查看当前快照仓库下所有快照
curl -X GET "localhost:9200/_snapshot/my_repo1/_all"如果一些快照不可用,会导致获取命令执行失败。可以通过设置布尔参数 ignore_unavailable 来指定返回当前可用的所有快照。
(7)删除快照\仓库
- 删除快照
curl -X DELETE "localhost:9200/_snapshot/my_repo1/snapshot_2"当一个快照从仓库中删除,ElasticSearch 将删除该快照关联的但不被其他快照使用的所有文件。如果在快照创建的时候执行快照删除操作,此快照创建进程将终止且所有该进程已创建的文件也将被清理。所以,快照删除操作可以用来取消错误启动的长时间运行的快照操作。
- 删除仓库
curl -X DELETE "localhost:9200/_snapshot/my_repo1"当一个仓库被注销时,ElasticSearch 只删除仓库存储快照的引用位置,快照本身没有被删除并且在原来的位置。
(8)快照恢复
curl -X POST "localhost:9200/_snapshot/存储库/快照名/_restore"默认情况下,快照中的所有索引将被恢复,集群状态不被恢复。可以通过在恢复请求中使用 indices 和 include_global_state 选项来指定要恢复的索引和允许恢复集群全局状态。索引列表支持多索引语法。rename_pattern 和 rename_replacement 选项在恢复时通过正则表达式来重命名索引。设置 include_aliases 为 false 可以防止与索引关联的别名被一起恢复。
curl -X POST "localhost:9200/_snapshot/my_backup/snapshot_1/_restore" -H 'Content-Type: application/json' -d'
{
"indices": "index_1,index_2",
"ignore_unavailable": true,
"include_global_state": true,
"rename_pattern": "index_(.+)",
"rename_replacement": "restored_index_$1"
}恢复操作可以在正常运行的集群上执行。已存在的索引只能在关闭状态下才能恢复,并且要跟快照中索引拥有相同数目的分片。还原操作自动打开关闭状态的索引,如果被还原索引在集群不存在,将创建新索引。如果集群状态通过 include_global_state (默认是 false)选项被还原,在集群中不存在的模板会被新增,已存在的同名模板会被快照中的模板替换。持久化设置会被添加到现有的持久化设置中。
(9)快照部分恢复
默认情况下,如果参与恢复操作的一个或者多个索引没有全部可用分片的快照,整个恢复操作将会失败。比如部分分片快照备份操作失败,上面的情况就会发生。这种情况依然可以通过设置 partial 为 true 来实现快照的恢复。注意在这种情况下,只有成功完成快照备份的分片才会被还原,而所有丢失的 其它分片将被创建成空分片。
在恢复过程中,大部分的索引配置会被覆盖。例如,下面的命令将恢复索引 index_1,不创建任何副本并切换回默认的索引刷新时间间隔:
curl -X POST "localhost:9200/_snapshot/my_backup/snapshot_1/_restore" -H 'Content-Type: application/json' -d'
{
"indices": "index_1",
"index_settings": {
"index.number_of_replicas": 0
},
"ignore_index_settings": [
"index.refresh_interval"
]
}(10)不同集群迁移流程
源集群
- 1、修改配置文件
elasticsearch.yml,path.repo: ["/data/elk/backup"] - 2、注册快照存储库
- 3、创建快照
目标集群
- 1、修改配置文件
elasticsearch.yml,path.repo: ["/data/elk/backup"] - 2、注册快照存储库
- 3、将源集群的存储库复制到目标集群的存储库中
- 4、执行快照恢复
