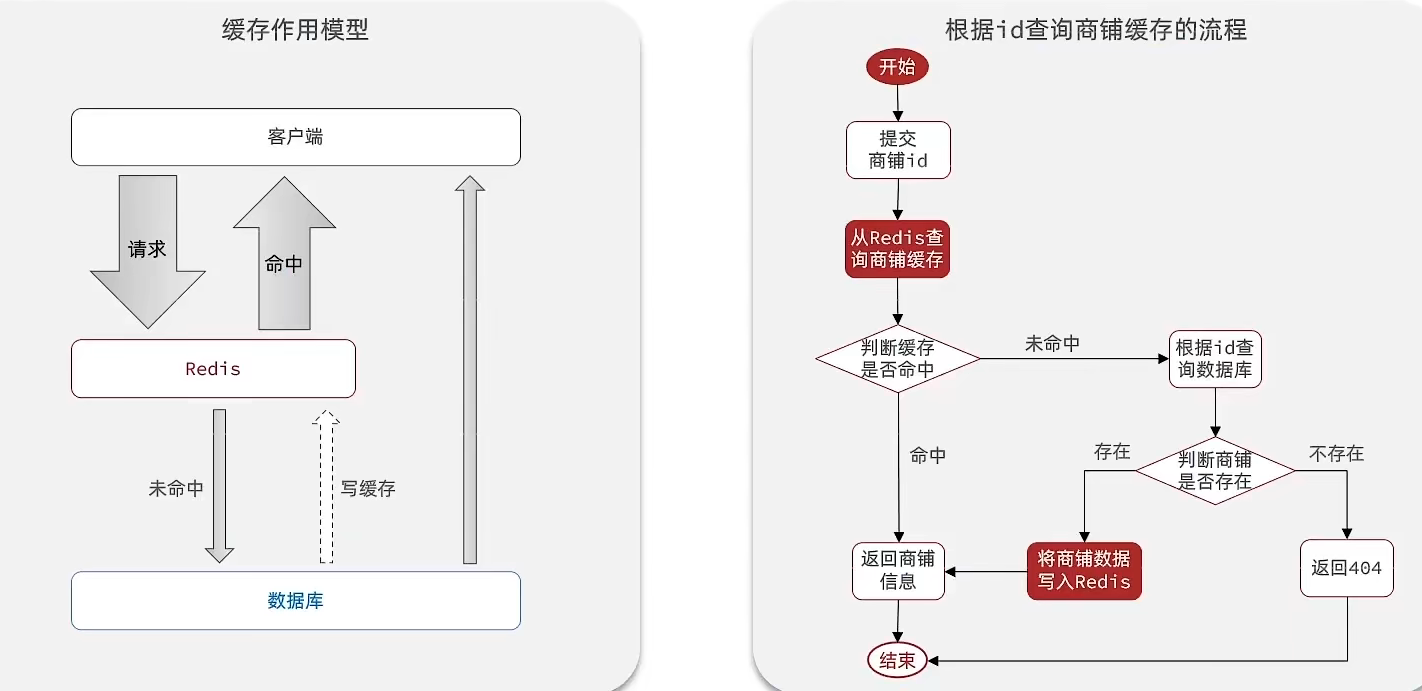
一、热点数据缓存
二、缓存更新策略(保证双写一致)
一致性就是数据保持一致,在分布式系统中,为多个节点中数据的值是一致的。
- 强一致性:要求系统写入什么,读出来的也会是什么,用户体验好,但实现起来往往对系统的性能影响大
- 弱一致性:约束系统在写入成功后,不承诺立即可以读到写入的值,也不承诺多久之后数据能够达到一致,但会尽可能地保证到某个时间级别(比如秒级别)后,数据能够达到一致状态
- 最终一致性:最终一致性是弱一致性的一个特例,系统会保证在一定时间内,能够达到一个数据一致的状态。
| 内存淘汰 | 超时剔除 | 主动更新(同步双写) | |
|---|---|---|---|
| 说明 | 不用自己维护,利用Rdis的内存淘汰机制,当内存不足时自动淘汰部分数据,下次查询时更新缓存 | 给缓存添加TTL超时时间,到期后自动删除缓存,下次查询时更新 | 在业务逻辑中修改数据库的同时,更新缓存 |
| 一致性 | 差 | 一般(最终一致性) | 好 |
| 维护成本 | 无(Redis 自动开启) | 低 | 高 |
下面介绍几种主动更新缓存的策略
1、手动更新
由缓存调用者,手动在更新数据库的同时更新缓存,并且设置超时时间(作为兜底方案)
需要考虑的问题:
(1)删除缓存还是更新缓存?
更新缓存:每次更新数据库都更新缓存,当多次操作之间,无人查询时,都是无效操作(×)
删除缓存:更新数据库时删除缓存,当有查询时,查询数据库,再添加到缓存(√)
(2)如何保持缓存与数据库的操作同时成功和失败(操作的原子性)
- 单体系统:将缓存和数据库操作在同一个事务
- 分布式系统(数据库、缓存不在同一服务):利用 TTC 等分布式事务方案
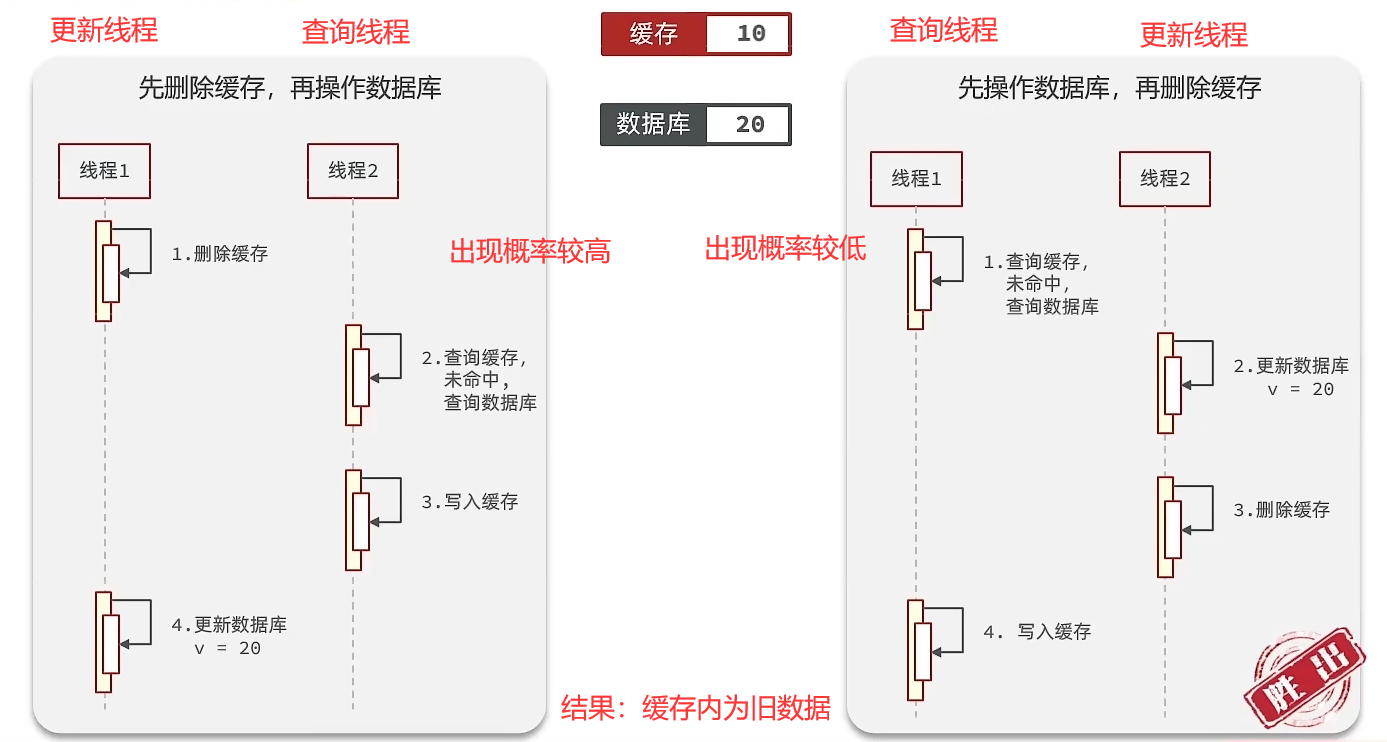
(3)先操作缓存还是先操作数据库
先删缓存,再操作数据库(×)
先操作数据库,再删缓存(√)
@Override
@Transactional
public Result update(Shop shop) {
Long id = shop.getId();
if (id == null) {
return Result.fail("店铺id不能为空");
}
// 1.更新数据库
updateById(shop);
// 2.删除缓存
stringRedisTemplate.delete(CACHE_SHOP_KEY + id);
return Result.ok();
}2、手动更新-延时双删
https://zhuanlan.zhihu.com/p/467410359
(1)延时双删
延时双删步骤
在写库前后都进行redis.del(key)操作,并且设定合理的超时时间。具体步骤是:
1)先删除缓存
2)再写数据库
3)休眠500毫秒(根据具体的业务时间来定)
4)再次删除缓存。
那么,这个500毫秒怎么确定的,具体该休眠多久呢?
需要评估自己的项目的读数据业务逻辑的耗时。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
当然,这种策略还要考虑 redis 和数据库主从同步的耗时。最后的写数据的休眠时间:则在读数据业务逻辑的耗时的基础上,加上几百ms即可。比如:休眠1秒。
(2)为什么要双删
首先,删除缓存是为了让其他事务读取数据的时候不会读到旧数据,而更新数据库前清除缓存和更新数据库后清除缓存解决的是不同时期的脏数据问题
只先删缓存的话,当我们在清除缓存和更新数据库间有事务查询缓存,此时没有缓存,数据库还没更新,所以缓存又更新为旧数据了
只后删缓存的话,在删除缓存之前读到的数据都是旧数据
那我们将两者综合起来的话,在更新前和更新后都进行删除,就可以很大程度上避免读到脏数据
那为什么要延时双删呢?我们考虑这样一种情况,在我们两次删除缓存之间更新数据库之前,B事务读到了数据库中的脏数据,但是他的时间片耗尽了,结果更新数据库的A事务进行了第二次清空缓存,时间片轮转回B时,B就会将旧数据缓存写进缓存当中去。此时我们使用延时双删策略,延后第二次删除缓存的时间,保证第二次删除缓存在所有的旧缓存之后,就可以确保不会有旧数据出现了
但是我们思考延时双删策略,此策略只能保证最终一致性,保证了第二次删除缓存之后的数据均为新数据,那第二次删除缓存之前还是能够读到旧数据的,如果对于数据没有强一致性要求的话延时双删已经足够了,但是如果对于数据有强一致性要求延时双删显然就不满足条件了,这个时候我们进一步优化的话可以考虑加锁操作,在写更新时阻塞读操作,带来的影响就是可以保证强一致性,但是吞吐量会下降。
(3)为什么要延时
为什么要延时呢?因为 mysql 和 redis 主从节点数据不是实时同步的,同步数据需要时间。
数据工作的大致流程:
- 服务节点删除 redis 主库数据。
- 服务节点修改 mysql 主库数据。
- 服务节点使得当前业务处理
等待一段时间,等 redis 和 mysql 主从节点数据同步成功。 - 服务节点从 redis 主库删除数据。
- 当前或其它服务节点读取 redis 从库数据,发现 redis 从库没有数据,从 mysql 从库读取数据,并写入 redis 主库。
3、整合第三方服务
缓存与数据库整合为一个服务,由该服务来维持数据的一致性。调用者无需关心缓存一致性问题。(如cancal)
4、只操作缓存
调用者操作数据时,只在缓存中操作,由其他线程(定时任务)异步的将缓存更新到数据库中。
优点:
两次数据库更新期间,缓存中多次插入数据,最后会合并为一次批量操作
两次数据库更新期间,缓存中多次修改同一条数据,最后只执行一次更新
缺点:
一致性有延迟
宕机数据丢失
三、缓存穿透
缓存穿透是指客户端请求的数据在缓存和数据库中不存在,这样缓存永远不会生效,这些请求都会被打倒数据库。
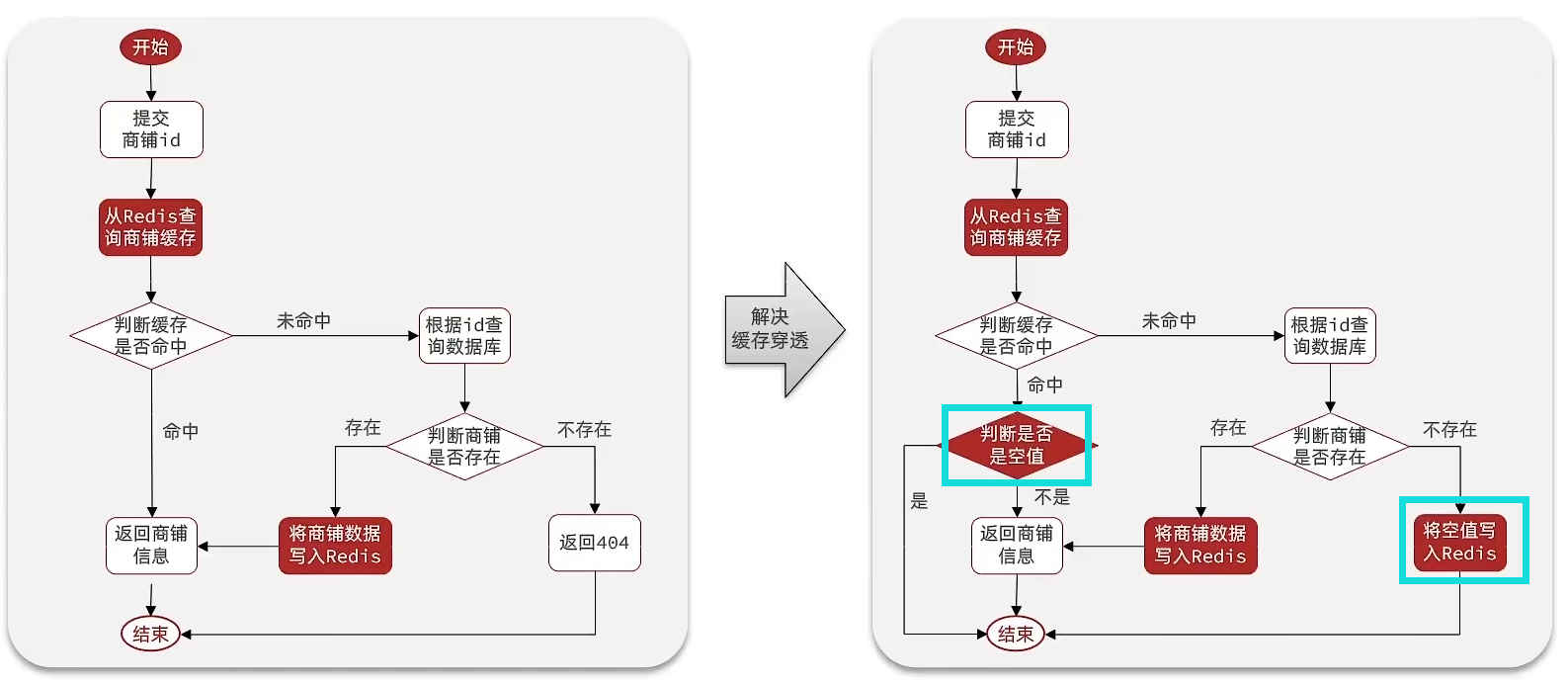
解决方式(1)– 缓存空对象(推荐)
用户请求空数据时,把空数据以空值存储到缓存中,并设置过期时间,这样用户再次请求空数据时,就不会在达到数据库了。
过期时间可以设置短一点,不必和真实数据一样长
- 优点:实现简单,维护方便
- 缺点:
- 额外的内存消耗
- 可能造成短期的不一致
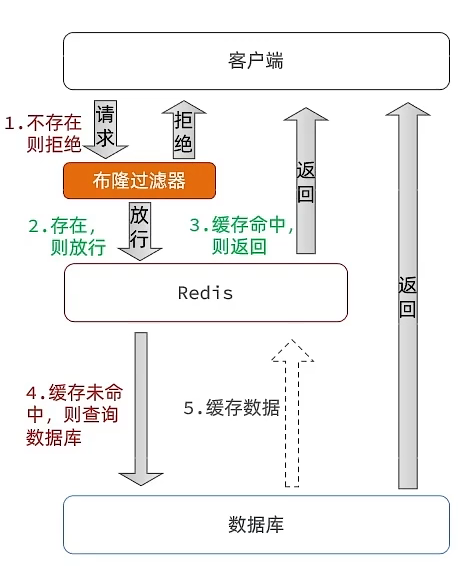
解决方案(2)– 布隆过滤器
布隆过滤器其实是一种数据结构,通过位(0或1)存储 key 是否存在,当判断 key 不存在时,则不放行,存在则放行。
- 优点:内存占用少,没有多余的 key
- 缺点:
- 实现复杂
- 存在误判的可能(布隆过滤器判断不存在,则一定不存在;判断存在,则不一定存在)
其他解决方案
以上两种属于被动的解决方案,建立在缓存穿透发生的基础上
以下属于主动的解决方案,适用于防止缓存穿透发生的
- 增加 id 的复杂度,避免被猜测到 id 规律
- 做好数据的基础格式校验
- 加强用户权限
- 做好热点参数的限流
四、缓存雪崩
缓存雪崩是指在同一时段大量的缓存 key 同时失效或者 Redis 服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案:
- 给不同的 key 的过期时间添加随机值
- 利用 Redis 集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
五、缓存击穿
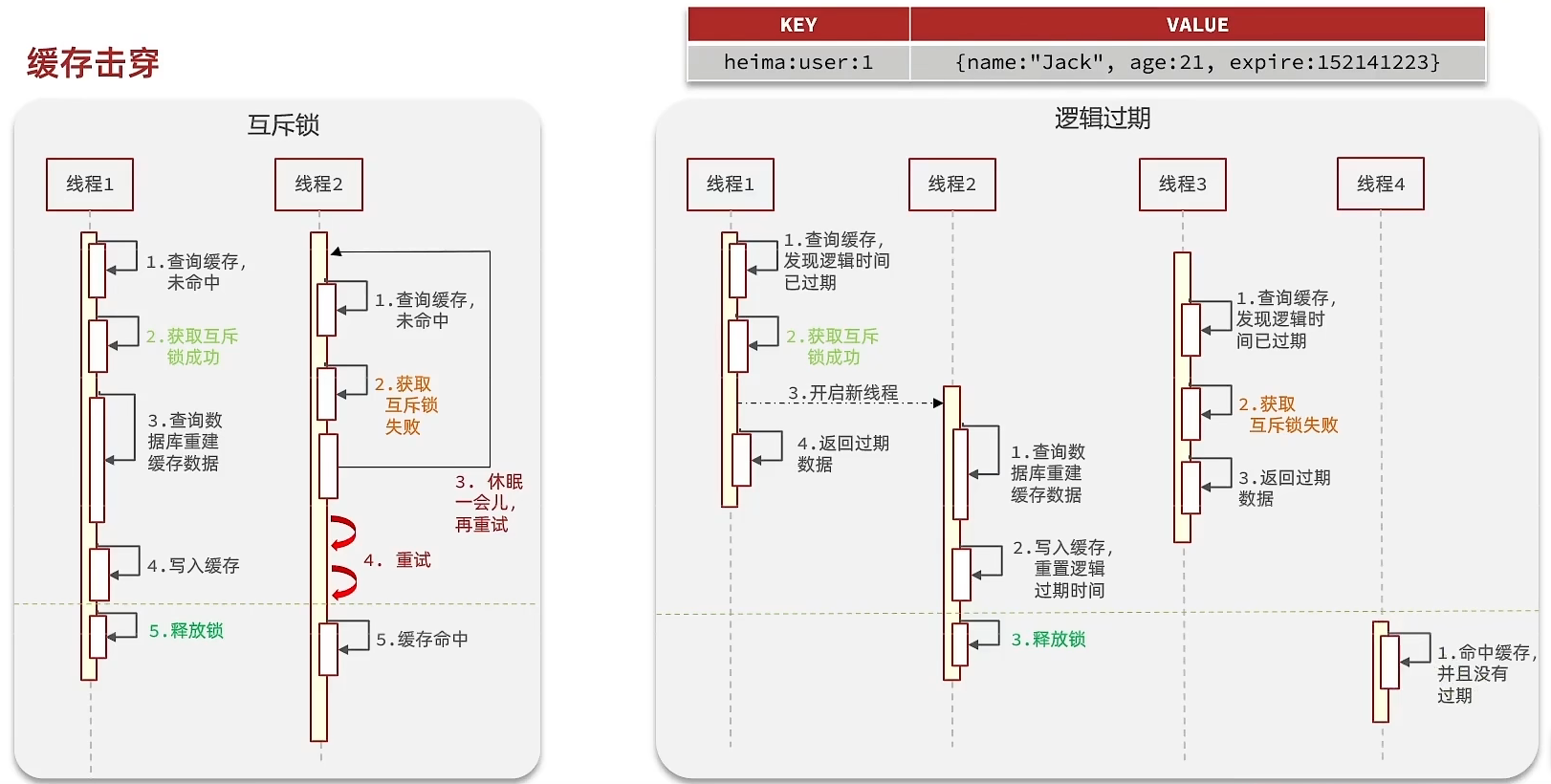
缓存击穿问题也叫热点 key 问题,就是一个呗高并发访问并且缓存重建业务较复杂的 key 突然失效了,无数的请求访问会在瞬间给数据库带来巨大的压力。
解决方案:互斥锁、逻辑过期
互斥锁缺点:缓存为命中时,只有一个线程在工作,其他所有线程只能等待,锁可用 redis 实现,需设置过期时间让制发生死锁
Boolean b = stringRedisTemplate.boundValueOps("user:info:lock").setIfAbsent("1", 5, TimeUnit.SECONDS);逻辑过期:是在互斥锁的基础上的升级版,即热点缓存不设置 TTL 过期时间,但需要设置一个逻辑过期字段。
对比
| 优点 | 缺点 | |
|---|---|---|
| 互斥锁 | - 没有额外的内存消耗 - 保证一致性 - 实现简单 |
- 线程需等待性能受影响 - 可能有死锁的风险 |
| 逻辑过期 | - 线程无需等待 | - 不保证一致性 - 有额外的内存消耗 - 实现复杂 |
互斥锁看中一致性,逻辑过期看中可用性
1、互斥锁实现
public <R, ID> R queryWithMutex(
String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit) {
String key = keyPrefix + id;
// 1.从redis查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
// 3.存在,直接返回
return JSONUtil.toBean(shopJson, type);
}
// 判断命中的是否是空值
if (shopJson != null) {
// 返回一个错误信息
return null;
}
// 4.实现缓存重建
// 4.1.获取互斥锁
String lockKey = LOCK_SHOP_KEY + id;
R r = null;
try {
boolean isLock = tryLock(lockKey);
// 4.2.判断是否获取成功
if (!isLock) {
// 4.3.获取锁失败,休眠并重试
Thread.sleep(50);
return queryWithMutex(keyPrefix, id, type, dbFallback, time, unit);
}
// 4.4.获取锁成功,根据id查询数据库
r = dbFallback.apply(id);
// 5.不存在,返回错误
if (r == null) {
// 将空值写入redis
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
// 返回错误信息
return null;
}
// 6.存在,写入redis
this.set(key, r, time, unit);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}finally {
// 7.释放锁
unlock(lockKey);
}
// 8.返回
return r;
}
private boolean tryLock(String key) {
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag);
}
private void unlock(String key) {
stringRedisTemplate.delete(key);
}2、逻辑过期
private final StringRedisTemplate stringRedisTemplate;
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
public <R, ID> R queryWithLogicalExpire(
String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit) {
String key = keyPrefix + id;
// 1.从redis查询商铺缓存
String json = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isBlank(json)) {
// 3.存在,直接返回
return null;
}
// 4.命中,需要先把json反序列化为对象
RedisData redisData = JSONUtil.toBean(json, RedisData.class);
R r = JSONUtil.toBean((JSONObject) redisData.getData(), type);
LocalDateTime expireTime = redisData.getExpireTime();
// 5.判断是否过期
if(expireTime.isAfter(LocalDateTime.now())) {
// 5.1.未过期,直接返回店铺信息
return r;
}
// 5.2.已过期,需要缓存重建
// 6.缓存重建
// 6.1.获取互斥锁
String lockKey = LOCK_SHOP_KEY + id;
boolean isLock = tryLock(lockKey);
// 6.2.判断是否获取锁成功
if (isLock){
// 6.3.成功,开启独立线程,实现缓存重建
CACHE_REBUILD_EXECUTOR.submit(() -> {
try {
// 查询数据库
R newR = dbFallback.apply(id);
// 重建缓存
this.setWithLogicalExpire(key, newR, time, unit);
} catch (Exception e) {
throw new RuntimeException(e);
}finally {
// 释放锁
unlock(lockKey);
}
});
}
// 6.4.返回过期的商铺信息
return r;
}六、全局唯一 ID
为了增加 ID 的安全性,不可直接使用 Redis的自增数值,还得拼接其他信息
ID 组成部分:
- 符号位:1 bit,永远是 0
- 时间戳:31 bit,秒为单位,可使用 69 年
- 序列号:32 bit,秒内的计数器,支持每秒产生 2 的 32 次方个不同的ID
生成全局唯一 ID 工具类
@Component
public class RedisIdWorker {
/**
* 开始时间戳
*/
private static final long BEGIN_TIMESTAMP = 1640995200L;
/**
* 序列号的位数
*/
private static final int COUNT_BITS = 32;
private StringRedisTemplate stringRedisTemplate;
public RedisIdWorker(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
public long nextId(String keyPrefix) {
// 1.生成时间戳
LocalDateTime now = LocalDateTime.now();
long nowSecond = now.toEpochSecond(ZoneOffset.UTC);
long timestamp = nowSecond - BEGIN_TIMESTAMP;
// 2.生成序列号
// 2.1.获取当前日期,精确到天,每天一个 key
String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
// 2.2.自增长
long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);
// 3.拼接并返回,先左移 32 位,在和 count 做或运算
return timestamp << COUNT_BITS | count;
}
}测试代码
@SpringBootTest
class HmDianPingApplicationTests {
@Resource
private CacheClient cacheClient;
@Resource
private ShopServiceImpl shopService;
@Resource
private RedisIdWorker redisIdWorker;
private ExecutorService es = Executors.newFixedThreadPool(500);
@Test
void testIdWorker() throws InterruptedException {
CountDownLatch latch = new CountDownLatch(300);
Runnable task = () -> {
for (int i = 0; i < 100; i++) {
long id = redisIdWorker.nextId("order");
System.out.println("id = " + id);
}
latch.countDown();
};
long begin = System.currentTimeMillis();
for (int i = 0; i < 300; i++) {
es.submit(task);
}
latch.await();
long end = System.currentTimeMillis();
System.out.println("time = " + (end - begin));
}
}七、消息队列
1、基于 list 实现
Redis 的 list 数据结构是一个双向链表,很容易模拟消息队列
队列的出口和入口不在同一边,因此可以利用:LPUSH 和 RPOP 来实现。
不过要注意的是,当消息队列中没有消息时 RPOP 操作会返回 null ,并不像 JVM 的阻塞队列那样会阻塞并等待消息
因此这里应该使用 BRPOP 来实现阻塞效果
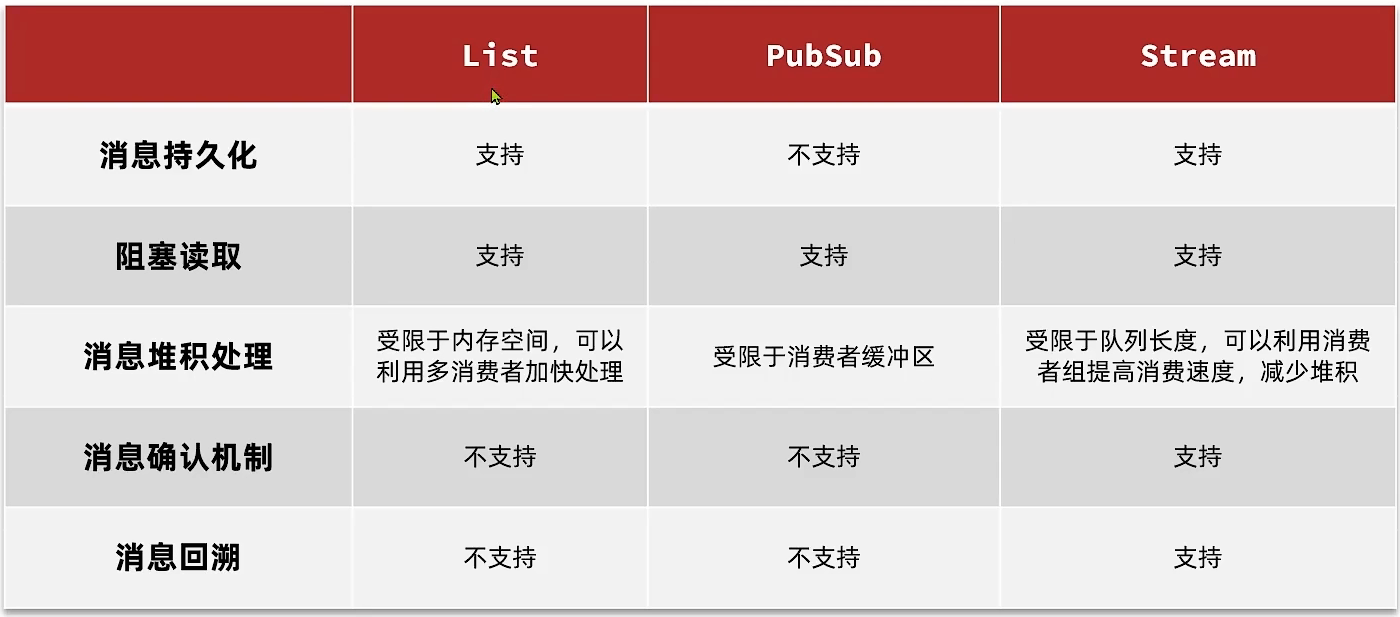
- 优点
- 利用 Redis 存储,不受限于 JVM 内存上限
- 基于 Redis 的持久化机制,数据安全性有保证
- 可以满足消息的有序性
- 缺点
- 无法避免消息的丢失
- 只支持单消费者
2、基于发布订阅
PubSub (发布订阅)是 Redis 2.0 版本引入的消息传递模型,顾名思义,消费者可以订阅一个或多个 channel ,生产者向对应 channel 发送消息后,所有订阅者都能收到小关消息。
SUBSCRIBE channel [channel]:订阅一个或多个频道PUBLISH channel msg:向一个频道发送消息PSUBSCRIBE pattern [pattern]:订阅与 pattern 通配符格式匹配的所有频道
# 发布消息
publish order.queue msg
# 订阅单个频道
subscribe order.queue
# 通配符模式订阅频道
psubscribe order.*- 优点
- 采用发布订阅模型,支持多生产、多消费
- 缺点
- 不支持数据持久化
- 无法避免消息丢失,发布消息时,无消费者接收时,消息会丢失
- 消费者消息堆积有上限,超出数据丢失
3、基于 Stream 的消息队列
(1)基本使用
Stream 是 Redis 5.0 引入的一种新数据类型,可实现一个功能完善的消息队列
发送消息
XADD key [NOMKSTREAM] [MAXLEN|MINID [=|~] threshold [LIMIT count]] *|ID field value [field value ...]key:消息队列名NOMKSTREAM:可选参数,如果队列不存在,是否自动创建队列,默认是自动创建[MAXLEN|MINID [=|~] threshold [LIMIT count] ]:可选参数,设置消息队列最大消息数量*|ID:消息的唯一 id,* 代表由 redis 自动生成。格式是 “时间戳-递增数字”,推荐直接用 *。field value [field value ...]:发送到队列中的消息,称为 Entry。格式是多个 key-value 键值对
案例:
# 创建名为 users 的队列,并向其中发送一个消息,内容是:{name=jack,age=21},并且使用 Redis 自动生成 id
XADD users * name jack age 21读取消息
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...][COUNT count]:可选参数,每次读取消息的最大数量[BLOCK milliseconds]:当没有消息时,是否阻塞、阻塞时长STREAMS key [key ...]:要从哪个消息队列读取,key 是队列名ID [ID ...]:起始 id,只返回大于该 id 的消息,0:代表从第一个消息开始;$:代表从最新的消息开始
案例:
XREAD COUNT 1 STREAMS s1 0该模式下的队列读取后数据不会删除,依然存在在队列中,上面这条语句重复读取时,都会读取到同一条消息,即第一条数据
XREAD COUNT 1 STREAMS s1 $上面这条语句,每次都会读取最新一条数据
XREAD COUNT 1 BLOCK 0 STREAMS s1 $阻塞等待读取最新消息,阻塞时间无限
注意
当定起始 ID 为 $ 时,代表读取最新的消息,如果我们处理一条消息的过程中,又有超过一条以上的消息到达队列,则下次获取时也只能获取到最新的一条,会出现漏读消息的情况
优缺点
- 消息可回溯
- 一个消息能被多个消费者读取
- 可以阻塞读取
- 有消息漏读的风险
(2)消费者组
消费者组(Consumer Group):将多个消费者划分到一个组中,监听同一个队列。
消息分流:消息队列中的消息会分流给组内的不同消费者,而不是重复消费,从而加快消息处理的速度。同组内的消费者为竞争关系,不会处理同一个消息,要想消息让多个消费者消费,只需要发布给多个组即可。
消息标示:消费者会维护一个标示,记录最后一个被处理的消息,哪怕消费者宕机重启,还会从标示之后读取消息。确保每一个消息都会被消费。
消息确认:消费者获取消息后,消息处于 pending 状态,并存入一个 pending-list 。当处理完成后需要通过 XACK 来确认消息,标记消息为已处理,才会从 pending-list 移除
消费者组操作
创建消费者组
XGROUP CREATE key groupName ID [MKSTREAM]- key:队列名
- groupName: 消费者组名称
- ID :起始 id 标识,$:最后一个消息,0:第一个消息
- [MKSTREAM]:队列不存在时自动创建队列
# 删除消费者组
XGROUP DESTORY key groupName
# 给指定的消费者组添加消费者
XGROUP CREATECONSUMER key groupname consumername
# 删除消费者组中指定的消费者
XGROUP DELCONSUMER key groupname consumername读取消息
指定用哪个消费者组中哪个消费者去读哪个队列
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]- group :消费组名
- consumer :消费者名称,如果消费者不存在,则自动创建
- count :本次查询最大数量
- BLOCK milliseconds : 当没有消息时最长等待时间
- NOACK :无需手动 ACK,获取到消息后自动确认
- STREAMS key : 指定队列名称
- ID :获取消息的起始 ID:
- “>” :从下一个未消费的消息开始(一般用这个)
- 其他:根据指定的 id 从 pending-list 中获取已消费但未确认的消息,例如 0 ,是从 pending-list 中的第一个消息开始,因为 pending-list 中消息确认后会移除,所以获取的永远是未确认的
确认消息
XACK key groupName ID [ID ...]- key :队列名
- groupName : 组名
- ID :消息的 id
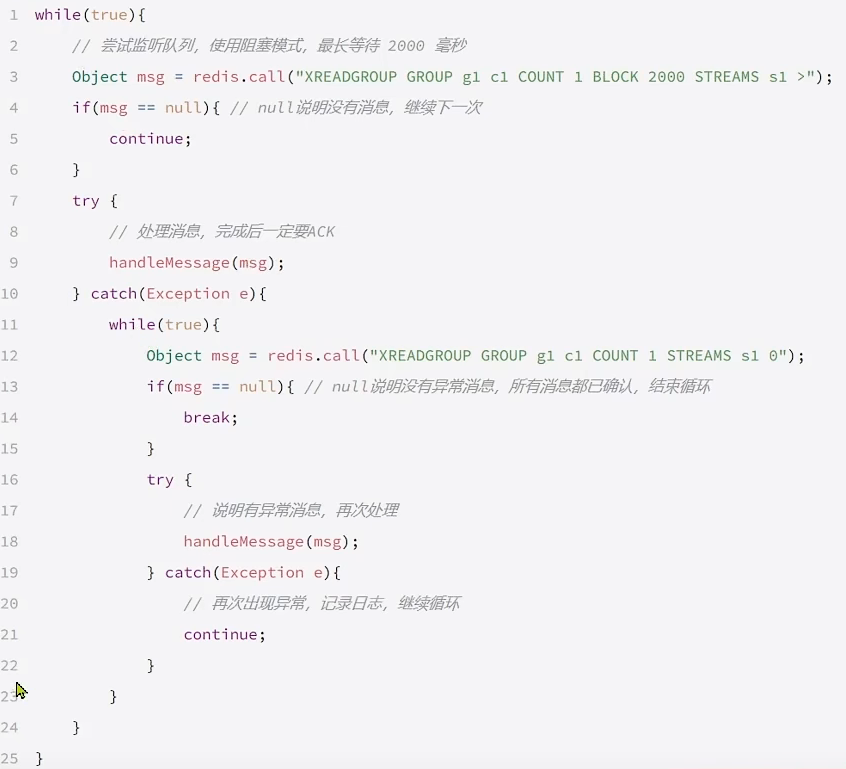
(3)Java 使用思路
伪代码
需求:
(1)创建一个 Stream 类型的消息队列,名为 stream.orders
(2)在用户下单后,直接向 stream.order 中添加消息
(3)项目启动时,开启线程任务,尝试获取 stream.orders 中的消息
(1)手动在redis中创建
创建队列和消费者组
XGROUP CREATE stream.orders g1 0 MKSTREAM或
// 创建消费者组、组已存在时再次创建会报错,故不推荐用 java 代码创建
String s = stringRedisTemplate.opsForStream().createGroup("stream.orders", "g1");
System.out.println(s); // OK(2)发送消息
java 代码中直接发送
HashMap<Object, Object> map = new HashMap<>();
map.put("orderId","123");
stringRedisTemplate.boundStreamOps("stream.orders").add(map);为了保证原子性,也可以在 Lua 脚本中发送
-- 1.参数列表
-- 1.1.优惠券id
local voucherId = ARGV[1]
-- 1.2.用户id
local userId = ARGV[2]
-- 1.3.订单id
local orderId = ARGV[3]
-- 2.数据key
-- 2.1.库存key
local stockKey = 'seckill:stock:' .. voucherId
-- 2.2.订单key
local orderKey = 'seckill:order:' .. voucherId
-- 3.脚本业务
-- 3.1.判断库存是否充足 get stockKey
if(tonumber(redis.call('get', stockKey)) <= 0) then
-- 3.2.库存不足,返回1
return 1
end
-- 3.2.判断用户是否下单 SISMEMBER orderKey userId
if(redis.call('sismember', orderKey, userId) == 1) then
-- 3.3.存在,说明是重复下单,返回2
return 2
end
-- 3.4.扣库存 incrby stockKey -1
redis.call('incrby', stockKey, -1)
-- 3.5.下单(保存用户)sadd orderKey userId
redis.call('sadd', orderKey, userId)
-- 3.6.发送消息到队列中, XADD stream.orders * k1 v1 k2 v2 ...
redis.call('xadd', 'stream.orders', '*', 'userId', userId, 'voucherId', voucherId, 'id', orderId)
return 0执行 Lua 脚本
private static final DefaultRedisScript<Long> SECKILL_SCRIPT;
static {
SECKILL_SCRIPT = new DefaultRedisScript<>();
SECKILL_SCRIPT.setLocation(new ClassPathResource("seckill.lua"));
SECKILL_SCRIPT.setResultType(Long.class);
}
public Result seckillVoucher(Long voucherId) {
Long userId = UserHolder.getUser().getId();
long orderId = redisIdWorker.nextId("order");
// 1.执行lua脚本
Long result = stringRedisTemplate.execute(
SECKILL_SCRIPT,
Collections.emptyList(),
voucherId.toString(), userId.toString(), String.valueOf(orderId)
);
int r = result.intValue();
// 2.判断结果是否为0
if (r != 0) {
// 2.1.不为0 ,代表没有购买资格
return Result.fail(r == 1 ? "库存不足" : "不能重复下单");
}
// 3.返回订单id
return Result.ok(orderId);
}(3)阻塞获取消息
private static final ExecutorService SECKILL_ORDER_EXECUTOR = Executors.newSingleThreadExecutor();
@PostConstruct
private void init() {
SECKILL_ORDER_EXECUTOR.submit(new VoucherOrderHandler());
}
private class VoucherOrderHandler implements Runnable {
@Override
public void run() {
while (true){
try {
// 获取消息队列中的订单信息, XREADGROUP GROUP g1 c1 COUNT 1 BLOCK 2000 STREAM stream.orders
List<MapRecord<String, Object, Object>> list = stringRedisTemplate.opsForStream().read(
Consumer.from("g1", "c1"),//创建消费者,参数1:组名,参数2:消费者名(应定义在yam文件中)
StreamReadOptions.empty().count(1).block(Duration.ofSeconds(2)),
StreamOffset.create("stream.orders", ReadOffset.lastConsumed())
);
if (CollectionUtils.isEmpty(list)){
// 如果为 null 说明没有消息,继续下一次循环
continue;
}
// 解析消息
MapRecord<String, Object, Object> record = list.get(0);
Map<Object, Object> value = record.getValue();
// 确认消息
stringRedisTemplate.opsForStream().acknowledge("stream.orders","g1",record.getId());
}catch (Exception e){
try{
// 获取 pending-list中的订单信息 XREADGROUP GROUP g1 c1 COUNT 1 STREAM stream.orders 0
List<MapRecord<String, Object, Object>> list = stringRedisTemplate.opsForStream().read(
Consumer.from("g1", "c1"),//创建消费者,参数1:组名,参数2:消费者名(应定义在yam文件中)
StreamReadOptions.empty().count(1),
StreamOffset.create("stream.orders", ReadOffset.from("0"))
);
if (CollectionUtils.isEmpty(list)){
// 没有异常消息
break;
}
// 解析消息
MapRecord<String, Object, Object> record = list.get(0);
// 确认消息
stringRedisTemplate.opsForStream().acknowledge("stream.orders","g1",record.getId());
}catch (Exception e2){
e2.printStackTrace();
// 如果怕抛太多异常,可在这里停一下
}
}
}
}
}4、三种方式对比
八、点赞功能
需求:
- 同一个用户只能点赞一次,再次点击取消点赞
- 如果当前用户已经点赞,则无法再次点赞
实现步骤:
- 给返回的 Blog 类中添加一个 isLike字段,标识是否被当前用户点赞
- 利用 Redis 的set 集合判断是否点赞过,未点赞过则点赞数+1,已点赞过则点赞数 -1
点赞、取消点赞
使用时间戳作为 zset 的分数,实现按时间排序
// 1.获取登录用户
Long userId = UserHolder.getUser().getId();
// 2.判断当前登录用户是否已经点赞
String key = BLOG_LIKED_KEY + id;
Double score = stringRedisTemplate.opsForZSet().score(key, userId.toString());
if (score == null) {
// 3.如果未点赞,可以点赞
// 3.1.数据库点赞数 + 1
boolean isSuccess = update().setSql("liked = liked + 1").eq("id", id).update();
// 3.2.保存用户到Redis的set集合 zadd key value score
if (isSuccess) {
stringRedisTemplate.opsForZSet().add(key, userId.toString(), System.currentTimeMillis());
}
} else {
// 4.如果已点赞,取消点赞
// 4.1.数据库点赞数 -1
boolean isSuccess = update().setSql("liked = liked - 1").eq("id", id).update();
// 4.2.把用户从Redis的set集合移除
if (isSuccess) {
stringRedisTemplate.opsForZSet().remove(key, userId.toString());
}
}
return Result.ok();获取前 5 个点赞的人
// 1.查询top5的点赞用户 zrange key 0 4
Set<String> top5 = stringRedisTemplate.opsForZSet().range(key, 0, 4);九、共同关注
单向关注的话直接使用 mysql ,创建一张表,存关注者id、被关注者id 即可。
共同关注采用的是 Redis 的 set 类型
SADD s1 m1 m2
SADD s2 m2 m3
SINTER s1 s2 # 返回 m2共同关注基本实现思路,单向关注时,不仅要存数据库,还得存到 redis,用户 id 为 key,关注目标为 value。
查询共同关注的时候,只需要获取2个用户 id 对应的 set 集合的交集即可
// 获取交集
Set<String> set = stringRedisTemplate.opsForSet().intersect("key1", "key2");十、关注推送
关注推送也叫做 Feed 流,直译为投喂,为用户持续提供沉浸式的体验,(无限下拉刷新获取新的信息),比如贴吧,下拉获取新的帖子
Feed 流产品有两种常见的模式
TimeLine:不做内容筛选,简单的按照内容发布时间排序,常用语好友或关注。例如朋友圈。- 优点:信息全面,不会确实,并且实现简单
- 缺点:信息噪音较多,用户不一定感兴趣,内容获取效率低
智能排序:利用智能算法屏蔽掉违规的、用户不感兴趣的内容。推送用户感兴趣的信息来吸引用户- 优点:投喂用户感兴趣的,用户粘度高,容易沉迷
- 缺点:如果算法不精确,可能起到反作用
1、TimeLine 模式
该模式有三种实现方案
- 拉模式:也叫读扩散
- 推模式:也叫写扩散
- 推拉模式:也叫读写混合
(1)读扩散

思路:每个人都有一个发件箱,发布帖子后,存在发件箱中,当用户要读取数据时,从关注列表的发件箱中获取并排序
优点:节省空间,每个消息只存储一份
缺点:每次读取都要拉取消息在做排序,延迟较高
(2)写扩散
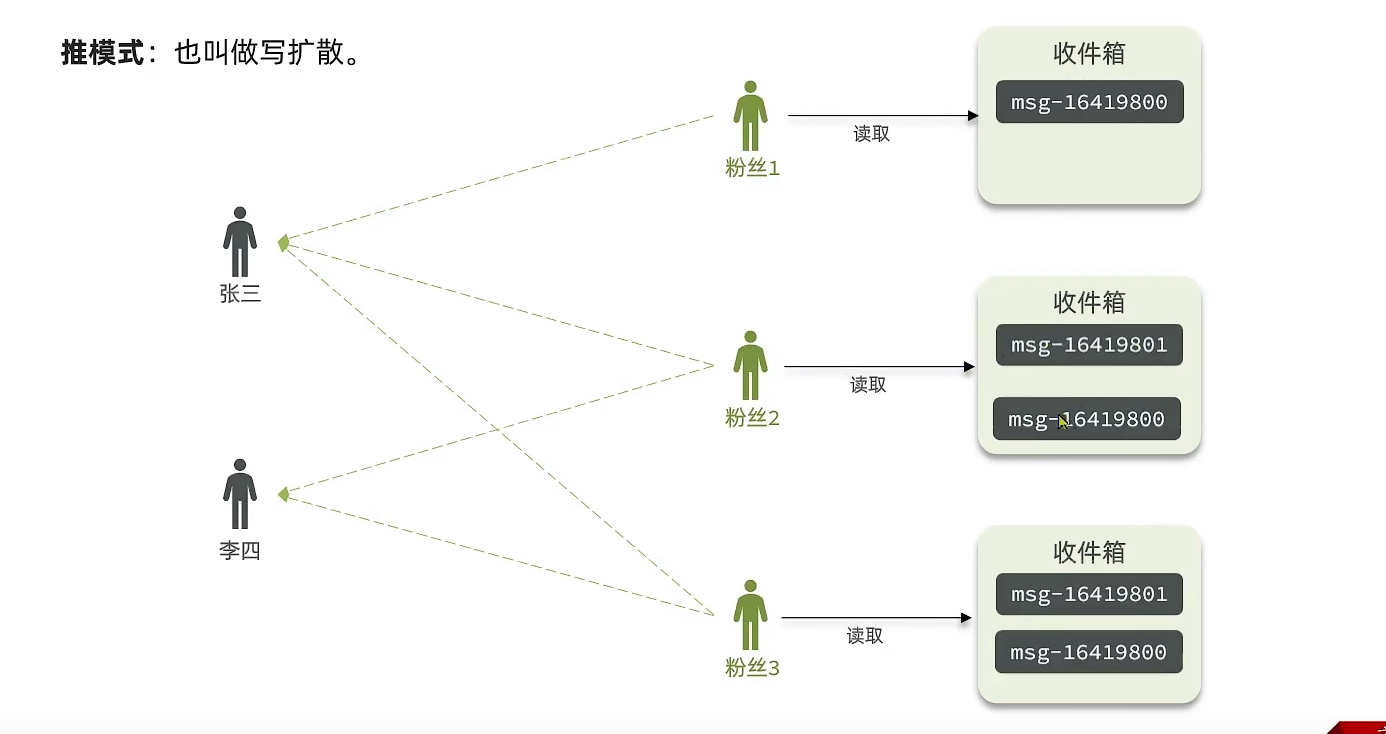
思路:每个人都有一个收件箱,当用户发布帖子时,帖子会发送到所有关注改用户的收件箱中,并排好序;用户读取时,只需要到自己的收件箱中读取。
优点:读取消息时的延迟较低
缺点:内存占用高,一个贴需要存储多份
(3)推拉模式
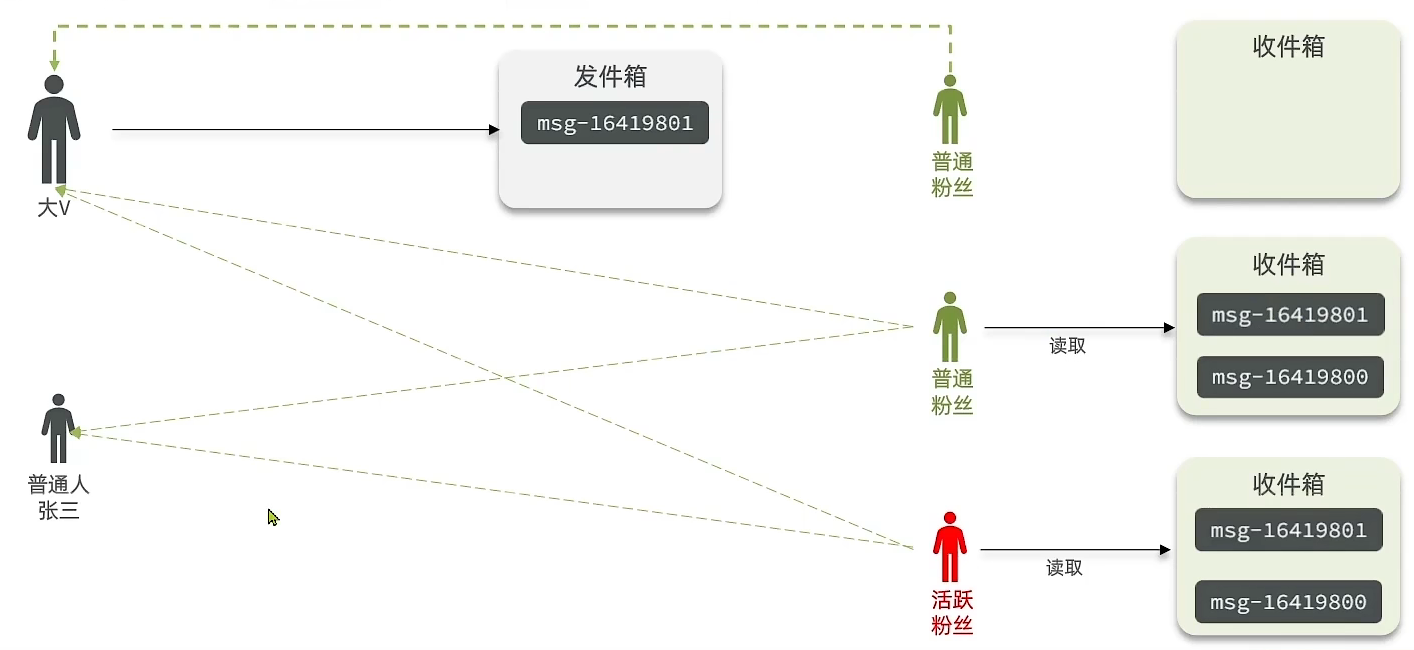
发布思路:
一个用户有2种身份,发布者和接收者
发布者分为大v和普通人,大v关注者较多
- 大v发布帖子时,使用的是推拉结合,因为大v粉丝较多,推模式占用内存过大
- 对于活跃粉丝,使用推模式,直接发送到活跃粉丝的收件箱
- 对于普通粉丝,大v在发帖时,不仅会推送到活跃粉丝的收件箱中,同时也会保存一份到自己的发件箱中,当普通粉丝要读取时,可到发件箱中读取即可
- 如果是普通人发贴时,使用的是推模式,因为普通人粉丝量不会太多,所以占用的内存也不会太多
(4)各模式使用场景
| 拉模式 | 推模式 | 推拉模式 | |
|---|---|---|---|
| 写比例 | 低 | 高 | 中 |
| 读比例 | 高 | 低 | 中 |
| 用户读取延迟 | 高 | 低 | 低 |
| 难度 | 复杂 | 简单 | 很复杂 |
| 场景 | 很少用,不推荐 | 用户少,无大v | 用户过千万,有大v |
(5)推模式的实现
需求:
- 在保存 blog 到数据库的同时,推送到粉丝的收件箱
- 收件箱满足可以根据时间戳排序
- 查询收件箱的数据时,实现分页查询
此处分页的实现需要使用滚动分页,即每次记录要查询的最后一个的索引

发布帖子
public Result saveBlog(Blog blog) {
// 1.获取登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
// 2.保存探店笔记
boolean isSuccess = save(blog);
if(!isSuccess){
return Result.fail("新增笔记失败!");
}
// 3.查询笔记作者的所有粉丝 select * from tb_follow where follow_user_id = ?
List<Follow> follows = followService.query().eq("follow_user_id", user.getId()).list();
// 4.推送笔记id给所有粉丝
for (Follow follow : follows) {
// 4.1.获取粉丝id
Long userId = follow.getUserId();
// 4.2.推送
String key = FEED_KEY + userId;
stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis());
}
// 5.返回id
return Result.ok(blog.getId());
}查看关注者帖子
滚动分页
offset:在上一次结果中与最小值一样的个数
public Result queryBlogOfFollow(Long max, Integer offset) {
// 1.获取当前用户
Long userId = UserHolder.getUser().getId();
// 2.查询收件箱 ZREVRANGEBYSCORE key Max Min LIMIT offset count
String key = FEED_KEY + userId;
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(key, 0, max, offset, 2);
// 3.非空判断
if (typedTuples == null || typedTuples.isEmpty()) {
return Result.ok();
}
// 4.解析数据:blogId、minTime(时间戳)、offset
List<Long> ids = new ArrayList<>(typedTuples.size());
long minTime = 0; // 2
int os = 1; // 2
for (ZSetOperations.TypedTuple<String> tuple : typedTuples) { // 5 4 4 2 2
// 4.1.获取id
ids.add(Long.valueOf(tuple.getValue()));
// 4.2.获取分数(时间戳)
long time = tuple.getScore().longValue();
if(time == minTime){
os++;
}else{
minTime = time;
os = 1;
}
}
// 5.根据id查询blog
String idStr = StrUtil.join(",", ids);
List<Blog> blogs = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list();
for (Blog blog : blogs) {
// 5.1.查询blog有关的用户
queryBlogUser(blog);
// 5.2.查询blog是否被点赞
isBlogLiked(blog);
}
// 6.封装并返回
ScrollResult r = new ScrollResult();
r.setList(blogs);
r.setOffset(os);
r.setMinTime(minTime);
return Result.ok(r);
}十一、附近的人
1、相关数据类型
GEO就是Geolocation的简写形式,代表地理坐标。Redis在3.2版本中加入了对GEO的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。
GEO 底层使用的是 sorted set,将地理坐标通过特定的算法转化为一串数字作为 sorted set 的 score
常见的命令有:
GEOADD:添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member)GEODIST:计算指定的两个点之间的距离并返回GEOHASH:将指定member的坐标转为hash字符串形式并返回GEOPOS:返回指定member的坐标GEORADIUS:指定圆心、半径,找到该圆内包含的所有member,并按照与圆心之间的距离排序后返回。6.2以后已废弃GEOSEARCH:在指定范围内搜索member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。6.2.新功能GEOSEARCHSTORE:与GEOSEARCH功能一致,不过可以把结果存储到一个指定的key。6.2.新功能
添加坐标数据
存储北京站、北京南站、北京西站的地理坐标,并算出距离
# 在key为g1下,添加三个坐标,分别是bjn、bjz、bjx
GEOADD g1 116.378248 39.865275 bjn 116.42803 39.903738 bjz 116.322287 39.893729 bjx获取指定位置的坐标
GEOPOS g1 bjz计算2点之间的距离
# 计算2点距离,参数:key、点1、点2、距离单位(默认m)
GEODIST g1 bjn bjx km所有某个点作为圆心的指定范围内的所有点
GEOSEARCH g1 FROM LONLAT 116.39704 39.909005 BYRADIUS 10 km WITHDIST2、java使用GEO
存储数据
RedisGeoCommands.GeoLocation<String> bjz = new RedisGeoCommands.GeoLocation<>("bjz",new Point(116.322287,39.893729));
RedisGeoCommands.GeoLocation<String> bjn = new RedisGeoCommands.GeoLocation<>("bjn",new Point(116.42803,39.903738));
RedisGeoCommands.GeoLocation<String> bjx = new RedisGeoCommands.GeoLocation<>("bjx",new Point(116.322287,39.893729));
ArrayList<RedisGeoCommands.GeoLocation<String>> locations = new ArrayList<>();
locations.add(bjz);
locations.add(bjn);
locations.add(bjx);
stringRedisTemplate.boundGeoOps("address").add(locations);查询数据
GeoResults<RedisGeoCommands.GeoLocation<String>> results = stringRedisTemplate.boundGeoOps("address").search(
GeoReference.fromCoordinate(116.322287, 39.893729), // 搜索中心坐标
new Distance(100 ,Metrics.KILOMETERS), // 搜索范围 100 km,默认单位 米
RedisGeoCommands.GeoRadiusCommandArgs.newGeoSearchArgs()
.includeDistance() // 返回结果带上距离
.limit(10) // 仅返回距离最近的10条数据,无法指定开始索引,需自行截取
);
if (results == null){
return;
}
List<GeoResult<RedisGeoCommands.GeoLocation<String>>> content = results.getContent();
for (GeoResult<RedisGeoCommands.GeoLocation<String>> geoLocationGeoResult : content) {
System.out.println(geoLocationGeoResult);
}3、查询附近店铺
需提前手动将店铺地址存储到 redis ,店铺 id 为 坐标名。
public Result queryShopByType(Integer typeId, Integer current, Double x, Double y) {
// 1.判断是否需要根据坐标查询
if (x == null || y == null) {
// 不需要坐标查询,按数据库查询
Page<Shop> page = query()
.eq("type_id", typeId)
.page(new Page<>(current, SystemConstants.DEFAULT_PAGE_SIZE));
// 返回数据
return Result.ok(page.getRecords());
}
// 2.计算分页参数
int from = (current - 1) * SystemConstants.DEFAULT_PAGE_SIZE;
int end = current * SystemConstants.DEFAULT_PAGE_SIZE;
// 3.查询redis、按照距离排序、分页。结果:shopId、distance
String key = SHOP_GEO_KEY + typeId;
GeoResults<RedisGeoCommands.GeoLocation<String>> results = stringRedisTemplate.opsForGeo() // GEOSEARCH key BYLONLAT x y BYRADIUS 10 WITHDISTANCE
.search(
key,
GeoReference.fromCoordinate(x, y),
new Distance(5000),
RedisGeoCommands.GeoSearchCommandArgs.newGeoSearchArgs().includeDistance().limit(end)
);
// 4.解析出id
if (results == null) {
return Result.ok(Collections.emptyList());
}
List<GeoResult<RedisGeoCommands.GeoLocation<String>>> list = results.getContent();
if (list.size() <= from) {
// 没有下一页了,结束
return Result.ok(Collections.emptyList());
}
// 4.1.截取 from ~ end的部分
List<Long> ids = new ArrayList<>(list.size());
Map<String, Distance> distanceMap = new HashMap<>(list.size());
list.stream().skip(from).forEach(result -> {
// 4.2.获取店铺id
String shopIdStr = result.getContent().getName();
ids.add(Long.valueOf(shopIdStr));
// 4.3.获取距离
Distance distance = result.getDistance();
distanceMap.put(shopIdStr, distance);
});
// 5.根据id查询Shop
String idStr = StrUtil.join(",", ids);
List<Shop> shops = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list();
for (Shop shop : shops) {
shop.setDistance(distanceMap.get(shop.getId().toString()).getValue());
}
// 6.返回
return Result.ok(shops);
}十二、BitMap实现签到
实现原理

1、BitMap用法
Redis 中是利用 string 类型数据结构实现 BitMap,因此最大上限是 512 M,装换为 bit 则是 2^32 个bit位
BitMap的操作命令如下:
| 命令 | 说明 |
|---|---|
| SETBIT | 向指定位置(offset)存入一个0或1 |
| GETBIT | 获取指定位置(offset)的 bit 值 |
| BITCOUNT | 统计 BitMap 中值为1的bit位的数量 |
| BITFIELD | 操作(查、改、自增)BitMap中bit数组中指定位置(offset)的值 |
| BITFIELD_RO | (Read Only)获取 BitMap 中bit数组,并以十进制形式返回 |
| BITOP | 将多个 BitMap 的结果做位运算(与、或、异或) |
| BITPOS | 查找 bit 数组中指定范围内第一个0 或 1出现的位置 |
具体用法如下
# 设置key为user1的bit数组中索引为0的值为1,前面的索引不设置值时,默认0
SETBIT user1 5 1
# 获取key为user1,索引为5的值
GETBIT user1 5
# 获取key为user1中bitMap中1的个数
BITCOUNT user1
# 范围批量获取数据,u2:表示获取2位无符号位,0是开始索引
# 从0开始获取2位,并返回二进制的值,11返回3
BITFIELD user1 GET u2 0
# 查询第一个1出现的位置
BITPOS user1 12、签到实现
public Result sign() {
// 1.获取当前登录用户
Long userId = UserHolder.getUser().getId();
// 2.获取日期
LocalDateTime now = LocalDateTime.now();
// 3.拼接key
String keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));
String key = USER_SIGN_KEY + userId + keySuffix;
// 4.获取今天是本月的第几天
int dayOfMonth = now.getDayOfMonth();
// 5.写入Redis SETBIT key offset 1
stringRedisTemplate.opsForValue().setBit(key, dayOfMonth - 1, true);
return Result.ok();
}3、统计连续签到天数
public Result signCount() {
// 1.获取当前登录用户
Long userId = UserHolder.getUser().getId();
// 2.获取日期
LocalDateTime now = LocalDateTime.now();
// 3.拼接key
String keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));
String key = USER_SIGN_KEY + userId + keySuffix;
// 4.获取今天是本月的第几天
int dayOfMonth = now.getDayOfMonth();
// 5.获取本月截止今天为止的所有的签到记录,返回的是一个十进制的数字 BITFIELD sign:5:202203 GET u14 0
List<Long> result = stringRedisTemplate.opsForValue().bitField(
key,
BitFieldSubCommands.create()
.get(BitFieldSubCommands.BitFieldType.unsigned(dayOfMonth)).valueAt(0)
);
if (result == null || result.isEmpty()) {
// 没有任何签到结果
return Result.ok(0);
}
Long num = result.get(0);
if (num == null || num == 0) {
return Result.ok(0);
}
// 6.循环遍历
int count = 0;
while (true) {
// 6.1.让这个数字与1做与运算,得到数字的最后一个bit位 // 判断这个bit位是否为0
if ((num & 1) == 0) {
// 如果为0,说明未签到,结束
break;
}else {
// 如果不为0,说明已签到,计数器+1
count++;
}
// 把数字右移一位,抛弃最后一个bit位,继续下一个bit位
num >>>= 1;
}
return Result.ok(count);
}十三、UV统计
1、Hyperloglog
两个概念
- UV:全称 Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网站的自然人。1 天内同一个用户多次访问,只记录一次
- PV:全称 Page View,也叫页面访问量,用户每访问网站的一个页面,记录一次 PV ,用户多次打开页面,则记录多次 PV ,往往用来衡量网站的流量
Hyperloglog 数据类型
Hyperloglog(HLL) 是从 Loglog 算法派生的概率算法,用于确定非常大的集合的技术,而不需要存储其所有值。
Redis 中的 HLL 是基于 string 结构实现的,单个 HLL 的内存永远小于 16 kb,内存占用低的令人发指!作为代价,其测量结果时概率性的,有小于 0.81 的误差。不过对于 UV统计来说,这完全可以忽略
用法:
# 向key=k1 中添加 5 个不同的元素
PFADD k1 e1 e2 e3 e4 e5
# 统计 k1 中有几个不同的元素
PFCOUNT k12、java操作
// 发送到Redis
stringRedisTemplate.opsForHyperLogLog().add("hl2", values);
// 统计数量
Long count = stringRedisTemplate.opsForHyperLogLog().size("hl2");即使插入超过 100 万条数据,占用内存也永远不会超过 16 kb

