一、Bloom Filter
布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。
面试关联:一般都会在回答缓存穿透,或者海量数据去重这个时候引出来
常用场景如下
- 爬虫过滤已抓到的url就不再抓,可用bloom filter过滤
- 垃圾邮件过滤。如果用哈希表,每存储一亿个 email地址,就需要 1.6GB的内存(用哈希表实现的具体办法是将每一个 email地址对应成一个八字节的信息指纹,然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email地址需要占用十六个字节。一亿个地址大约要 1.6GB,即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB的内存。而Bloom Filter只需要哈希表 1/8到 1/4 的大小就能解决同样的问题。
- 防止缓存击穿
优点:
- 所占空间小(并不存储真正的数据),空间效率高
- 查询时间短
缺点:
- 元素添加到数组中后,不能被删除
- 有一定的误判率
二、布隆过滤器原理
1、原理
本质:一个空的2进制数组(初始全为0,只存0和1)
插入:一个key,经过k个hash函数运算后,得到k个值,将2进制数组对应下标的位置置为1。
查询:将key同样进行k个hash,去2进制数组比对对应下标位置的值,
- 全为1则可能存在该key;
- 不全为1,则一定不存在该key
不能删除元素
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
Bloom Filter跟单哈希函数Bit-Map不同之处在于:Bloom Filter使用了k个哈希函数,每个字符串跟k个bit对应。从而降低了冲突的概率。
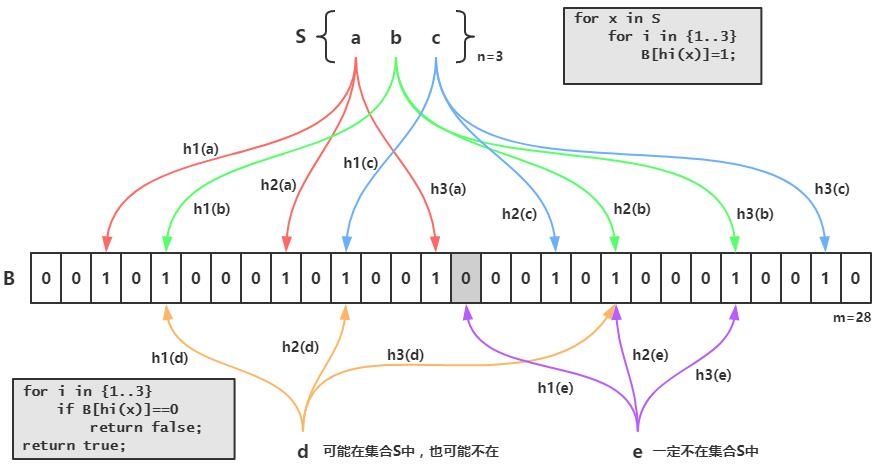
简单的说一下就是我们先把我们数据库的数据都加载到我们的过滤器中,比如数据库的id现在有:1、2、3
那就用id:1 为例子他在上图中经过三次hash之后,把三次原本值0的地方改为1
下次我进来查询如果id也是1 那我就把1拿去三次hash 发现跟上面的三个位置完全一样,那就能证明过滤器中有1的
反之如果不一样就说明不存在了
2、缺点
bloom filter之所以能做到在时间和空间上的效率比较高,是因为牺牲了判断的准确率、删除的便利性
- 存在误判,可能要查到的元素并没有在容器中,但是hash之后得到的k个位置上值都是1。如果bloom filter中存储的是黑名单,那么可以通过建立一个白名单来存储可能会误判的元素。
- 删除困难。一个放入容器的元素映射到bit数组的k个位置上是1,删除的时候不能简单的直接置为0,可能会影响其他元素的判断。
3、案例:防止缓存击穿
缓存穿透是指客户端请求的数据在缓存和数据库中不存在,这样缓存永远不会生效,这些请求都会被打倒数据库。
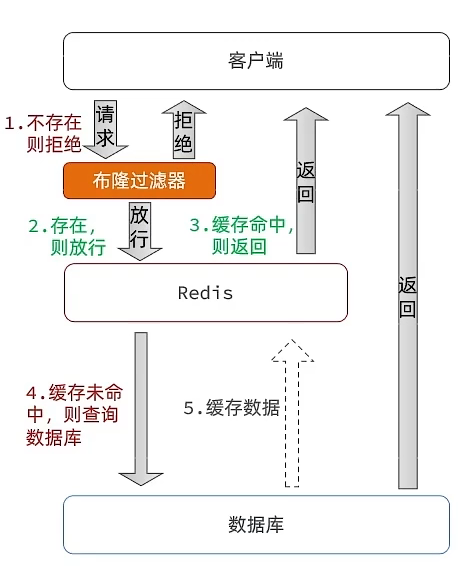
简单来说就是你数据库的id都是1开始然后自增的,那我知道你接口是通过id查询的,我就拿负数去查询,这个时候,会发现缓存里面没这个数据,我又去数据库查也没有,一个请求这样,100个,1000个,10000个呢?你的DB基本上就扛不住了,如果在缓存里面加上这个,是不是就不存在了,你判断没这个数据就不去查了,直接return一个数据为空不就好了嘛。
三、自定义实现Bloom Filter
Hutool 也有提供布隆过滤器的工具类 BloomFilterUtil
import java.util.BitSet;
public class MyBloomFilter {
/**
* 位数组的大小
*/
private static final int DEFAULT_SIZE = 2 << 24;
/**
* 通过这个数组可以创建 6 个不同的哈希函数
*/
private static final int[] SEEDS = new int[]{5, 17, 48, 73, 93, 132};
/**
* 位数组。数组中的元素只能是 0 或者 1
*/
private BitSet bits = new BitSet(DEFAULT_SIZE);
/**
* 存放包含 hash 函数的类的数组
*/
private SimpleHash[] func = new SimpleHash[SEEDS.length];
/**
* 初始化多个包含 hash 函数的类的数组,每个类中的 hash 函数都不一样
*/
public MyBloomFilter() {
// 初始化多个不同的 Hash 函数
for (int i = 0; i < SEEDS.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, SEEDS[i]);
}
}
/**
* 添加元素到位数组
*/
public void add(Object value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
/**
* 判断指定元素是否存在于位数组
*/
public boolean contains(Object value) {
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(value));
}
return ret;
}
/**
* 静态内部类。用于 hash 操作!
*/
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
/**
* 计算 hash 值
*/
public int hash(Object value) {
int h;
return (value == null) ? 0 : Math.abs(seed * (cap - 1) & ((h = value.hashCode()) ^ (h >>> 16)));
}
}
}四、Guava实现Bloom Filter
布隆过滤器有许多实现与优化,Guava中就提供了一种Bloom Filter的实现。
在使用bloom filter时,绕不过的两点是预估数据量n以及期望的误判率fpp
在实现bloom filter时,绕不过的两点就是hash函数的选取以及bit数组的大小。
对于一个确定的场景,我们预估要存的数据量为n,期望的误判率为fpp,然后需要计算我们需要的Bit数组的大小m,以及hash函数的个数k,并选择hash函数
错误率越大,所需空间和时间越小,错误率越小,所需空间和时间约大
Bit数组大小选择
根据预估数据量n以及误判率fpp,bit数组大小的m的计算方式: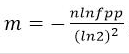
哈希函数选择
由预估数据量n以及bit数组长度m,可以得到一个hash函数的个数k: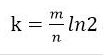
哈希函数的选择对性能的影响应该是很大的,一个好的哈希函数要能近似等概率的将字符串映射到各个Bit。选择k个不同的哈希函数比较麻烦,一种简单的方法是选择一个哈希函数,然后送入k个不同的参数。
哈希函数个数k、位数组大小m、加入的字符串数量n的关系可以参考Bloom Filters - the math,Bloom_filter-wikipedia
要使用BloomFilter,需要引入guava包:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency> 测试分两步:
1、往过滤器中放一百万个数,然后去验证这一百万个数是否能通过过滤器
2、另外找一万个数,去检验漏网之鱼的数量
/**
* 测试布隆过滤器(可用于redis缓存穿透)
*/
public class TestBloomFilter {
private static int total = 1000000;
private static BloomFilter<Integer> bf = BloomFilter.create(Funnels.integerFunnel(), total);
// private static BloomFilter<Integer> bf = BloomFilter.create(Funnels.integerFunnel(), total, 0.001);
public static void main(String[] args) {
// 初始化1000000条数据到过滤器中
for (int i = 0; i < total; i++) {
bf.put(i);
}
// 匹配已在过滤器中的值,是否有匹配不上的
for (int i = 0; i < total; i++) {
if (!bf.mightContain(i)) {
System.out.println("有坏人逃脱了~~~");
}
}
// 匹配不在过滤器中的10000个值,有多少匹配出来
int count = 0;
for (int i = total; i < total + 10000; i++) {
if (bf.mightContain(i)) {
count++;
}
}
System.out.println("误伤的数量:" + count);
}
}运行结果:

运行结果表示,遍历这一百万个在过滤器中的数时,都被识别出来了。一万个不在过滤器中的数,误伤了320个,错误率是0.03左右。
看下BloomFilter的源码:
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, int expectedInsertions) {
return create(funnel, (long) expectedInsertions);
}
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions) {
return create(funnel, expectedInsertions, 0.03); // FYI, for 3%, we always get 5 hash functions
}
public static <T> BloomFilter<T> create(
Funnel<? super T> funnel, long expectedInsertions, double fpp) {
return create(funnel, expectedInsertions, fpp, BloomFilterStrategies.MURMUR128_MITZ_64);
}
static <T> BloomFilter<T> create(
Funnel<? super T> funnel, long expectedInsertions, double fpp, Strategy strategy) {
......
}BloomFilter一共四个create方法,不过最终都是走向第四个。看一下每个参数的含义:
funnel:数据类型(一般是调用Funnels工具类中的)
expectedInsertions:期望插入的值的个数
fpp 错误率(默认值为0.03)
strategy 哈希算法
五、Redis实现Bloom Filter
1、插件安装
在 Redis 4.0 版本之后,布隆过滤器才作为插件被正式使用。布隆过滤器需要单独安装,下面介绍安装 RedisBloom 的几种方法:
(1)docker安装
docker 安装布隆过滤器是最简单、快捷的一种方式:
docker pull redislabs/rebloom:latest
docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest
docker exec -it redis-redisbloom bash
redis-cli
#测试是否安装成功
127.0.0.1:6379> bf.add www.baidu.com hello(2)直接编译安装
下载地址:https://github.com/RedisBloom/RedisBloom
# 拉取源代码,并切换分支,因为官方提供的下载包中文件有缺失,建议直接用git拉源代码
git clone https://github.com/RedisBloom/RedisBloom.git
git tag
git checkout v2.2.18
# 执行编译命令,生成redisbloom.so 文件:
make
# 拷贝至redis指定目录
cp redisbloom.so /usr/local/redis/bin/redisbloom.so在redis配置文件 redis.conf 里加入以下配置:/moules 搜索到外部 modules 模块
添加下面代码
loadmodule /usr/local/redis/bin/redisbloom.so配置完成后重启redis服务:
sudo /etc/init.d/redis-server restart2、常用命令
| 命令 | 说明 |
|---|---|
| bf.add | 只能添加元素到布隆过滤器 |
| bf.exists | 判断某个元素是否在于布隆过滤器中 |
| bf.madd | 同时添加多个元素到布隆过滤器 |
| bf.mexists | 同时判断多个元素是否存在于布隆过滤器中 |
| bf.reserve | 以自定义的方式设置布隆过滤器参数值,共有 3 个参数分别是 key、error_rate(错误率)、initial_size(初始大小) |
示例
# 将指定元素添加到 urls 这个布隆过滤器中
bf.add urls www.baidu.com
(integer) 1
# 判断指定元素是否在 urls 过滤器中存在
bf.exists urls www.baidu.com
(integer) 1
# 批量添加
bf.madd urls www.taobao.com www.123qq.com
1) (integer) 1
2) (integer) 1
# 批量判断存在
bf.mexists urls www.jd.com www.taobao.com
1) (integer) 0
2) (integer) 13、参数调整
错误率越低,所需要的空间也会越大,因此就需要我们尽可能精确的估算元素数量,避免空间的浪费。我们也要根据具体的业务来确定错误率的许可范围,对于不需要太精确的业务场景,错误率稍微设置大一点也可以。
布隆过滤器存在误判的情况,在 redis 中有两个值决定布隆过滤器的准确率:
error_rate:允许布隆过滤器的错误率,这个值越低过滤器的位数组的大小越大,占用空间也就越大。initial_size:布隆过滤器可以储存的元素个数,当实际存储的元素个数超过这个值之后,过滤器的准确率会下降。
redis 中有一个命令可以来设置这两个值:
bf.reserve urls 0.01 100三个参数的含义:
- 第一个值是过滤器的名字。
- 第二个值为
error_rate的值。 - 第三个值为
initial_size的值。
使用这个命令要注意一点:执行这个命令之前过滤器的名字应该不存在,如果执行之前就存在会报错:(error) ERR item exists
4、RedisTemplate操作
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.data.redis.core.script.RedisScript;
import org.springframework.stereotype.Component;
import java.util.Collections;
import java.util.List;
@Component
public class RedisBloomFilterUtil {
@Autowired
private StringRedisTemplate redisTemplate;
private static final RedisScript<Boolean> bfReserveScript = new DefaultRedisScript<>("return redis.call('bf.reserve', KEYS[1], ARGV[1], ARGV[2])", Boolean.class);
private static final RedisScript<Boolean> bfAddScript = new DefaultRedisScript<>("return redis.call('bf.add', KEYS[1], ARGV[1])", Boolean.class);
private static final RedisScript<Boolean> bfExistsScript = new DefaultRedisScript<>("return redis.call('bf.exists', KEYS[1], ARGV[1])", Boolean.class);
private static final String bfMaddScript = "return redis.call('bf.madd', KEYS[1], %s)";
private static final String bfMexistsScript = "return redis.call('bf.mexists', KEYS[1], %s)";
/**
* 设置错误率和大小(需要在添加元素前调用,若已存在元素,则会报错)
* 错误率越低,需要的空间越大
* @param key
* @param errorRate 错误率,默认0.01
* @param initialSize 默认100,预计放入的元素数量,当实际数量超出这个数值时,误判率会上升,尽量估计一个准确数值再加上一定的冗余空间
* @return
*/
public Boolean bfReserve(String key, double errorRate, int initialSize){
return redisTemplate.execute(bfReserveScript, Collections.singletonList(key), String.valueOf(errorRate), String.valueOf(initialSize));
}
/**
* 添加元素
* @param key
* @param value
* @return true表示添加成功,false表示添加失败(存在时会返回false)
*/
public Boolean bfAdd(String key, String value){
return redisTemplate.execute(bfAddScript, Collections.singletonList(key), value);
}
/**
* 查看元素是否存在(判断为存在时有可能是误判,不存在是一定不存在)
* @param key
* @param value
* @return true表示存在,false表示不存在
*/
public Boolean bfExists(String key, String value){
return redisTemplate.execute(bfExistsScript, Collections.singletonList(key), value);
}
/**
* 批量添加元素
* @param key
* @param values
* @return 按序 1表示添加成功,0表示添加失败
*/
public List<Integer> bfMadd(String key, String... values){
return redisTemplate.execute(this.generateScript(bfMaddScript, values), Collections.singletonList(key), values);
}
/**
* 批量检查元素是否存在(判断为存在时有可能是误判,不存在是一定不存在)
* @param key
* @param values
* @return 按序 1表示存在,0表示不存在
*/
public List<Integer> bfMexists(String key, String... values){
return redisTemplate.execute(this.generateScript(bfMexistsScript, values), Collections.singletonList(key), values);
}
private RedisScript<List> generateScript(String script, String[] values) {
StringBuilder sb = new StringBuilder();
for(int i = 1; i <= values.length; i ++){
if(i != 1){
sb.append(",");
}
sb.append("ARGV[").append(i).append("]");
}
return new DefaultRedisScript<>(String.format(script, sb.toString()), List.class);
}
}5、Redisson
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.6.5</version>
</dependency>public class RedissonBloomFilter {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
//config.useSingleServer().setPassword("");
// 构造Redisson
RedissonClient redissonClient = Redisson.create(config);
// 初始化布隆过滤器:预计元素为100000000L个,误差率为3%
RBloomFilter<Object> bloomFilter = redissonClient.getBloomFilter("phoneList");
bloomFilter.tryInit(100000000L, 0.03);
// 将号码插入到布隆过滤器中
bloomFilter.add("10086");
// 判断下面的号码是否在布隆过滤器中
System.out.println(bloomFilter.contains("10000"));
System.out.println(bloomFilter.contains("10086"));
}
}
