https://www.yuque.com/leifengyang/oncloud/ctiwgo
https://www.yuque.com/fairy-era/yg511q/hg3u04#5251abc9
一、Kubernetes
1、介绍
Kubernetes(k8s)中文文档 目录_Kubernetes中文社区
kubernetes,简称K8s,是用8代替名字中间的8个字符“ubernete”而成的缩写。是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署,规划,更新,维护的一种机制。
Kubernetes是Google开源的一个容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。在生产环境中部署一个应用程序时,通常要部署该应用的多个实例以便对应用请求进行负载均衡。
在Kubernetes中,我们可以创建多个容器,每个容器里面运行一个应用实例,然后通过内置的负载均衡策略,实现对这一组应用实例的管理、发现、访问,而这些细节都不需要运维人员去进行复杂的手工配置和处理。
kubernetes具有以下特性:
- 服务发现和负载均衡
Kubernetes 可以使用 DNS 名称或自己的 IP 地址公开容器,如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。 - 存储编排
Kubernetes 允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。 - 自动部署和回滚
你可以使用 Kubernetes 描述已部署容器的所需状态,它可以以受控的速率将实际状态 更改为期望状态。例如,你可以自动化 Kubernetes 来为你的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。 - 自动完成装箱计算
Kubernetes 允许你指定每个容器所需 CPU 和内存(RAM)。 当容器指定了资源请求时,Kubernetes 可以做出更好的决策来管理容器的资源。 - 自我修复
Kubernetes 重新启动失败的容器、替换容器、杀死不响应用户定义的 运行状况检查的容器,并且在准备好服务之前不将其通告给客户端。 - 密钥与配置管理
Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
Kubernetes 为你提供了一个可弹性运行分布式系统的框架。 Kubernetes 会满足你的扩展要求、故障转移、部署模式等。 例如,Kubernetes 可以轻松管理系统的 Canary 部署。
文档:https://kubernetes.io/zh-cn/docs/concepts/overview/components/
2、组件架构
当你部署完 Kubernetes,便拥有了一个完整的集群。
一组工作机器,称为 节点, 会运行容器化应用程序。每个集群至少有一个工作节点。
工作节点会托管 Pod ,而 Pod 就是作为应用负载的组件。 控制平面管理集群中的工作节点和 Pod。 在生产环境中,控制平面通常跨多台计算机运行, 一个集群通常运行多个节点,提供容错性和高可用性。
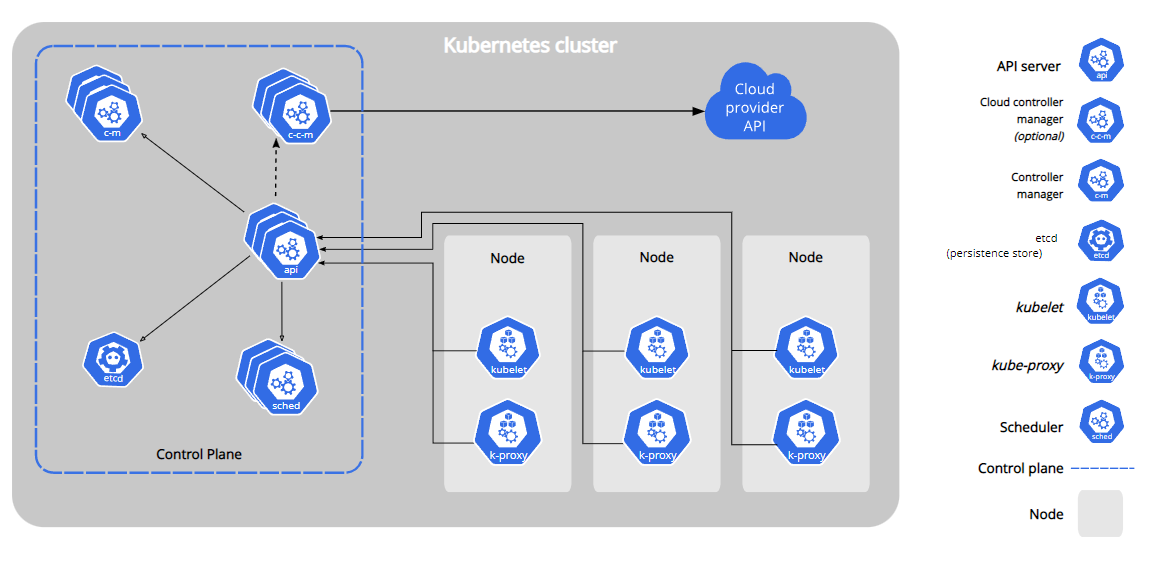
(1)控制平面组件(Control Plane Components)
控制平面的组件对集群做出全局决策(比如调度),以及检测和响应集群事件(例如,当不满足部署的 replicas 字段时,启动新的 pod)。
控制平面组件可以在集群中的任何节点上运行。 然而,为了简单起见,设置脚本通常会在同一个计算机上启动所有控制平面组件, 并且不会在此计算机上运行用户容器。 请参阅使用 kubeadm 构建高可用性集群 中关于多 VM 控制平面设置的示例。
kube-apiserver
API 服务器是 Kubernetes 控制面的组件, 该组件公开了 Kubernetes API。 API 服务器是 Kubernetes 控制面的前端。
Kubernetes API 服务器的主要实现是 kube-apiserver。 kube-apiserver 设计上考虑了水平伸缩,也就是说,它可通过部署多个实例进行伸缩。 你可以运行 kube-apiserver 的多个实例,并在这些实例之间平衡流量。
etcd
etcd 是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库。
您的 Kubernetes 集群的 etcd 数据库通常需要有个备份计划。
要了解 etcd 更深层次的信息,请参考 etcd 文档。
kube-scheduler
控制平面组件,负责监视新创建的、未指定运行节点(node)的 Pods,选择节点让 Pod 在上面运行。
调度决策考虑的因素包括单个 Pod 和 Pod 集合的资源需求、硬件/软件/策略约束、亲和性和反亲和性规范、数据位置、工作负载间的干扰和最后时限。
kube-controller-manager
在主节点上运行 控制器 的组件。
从逻辑上讲,每个控制器都是一个单独的进程, 但是为了降低复杂性,它们都被编译到同一个可执行文件,并在一个进程中运行。
这些控制器包括:
- 节点控制器(Node Controller): 负责在节点出现故障时进行通知和响应
- 任务控制器(Job controller): 监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成
- 端点控制器(Endpoints Controller): 填充端点(Endpoints)对象(即加入 Service 与 Pod)
- 服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名空间创建默认帐户和 API 访问令牌
cloud-controller-manager
云控制器管理器是指嵌入特定云的控制逻辑的 控制平面组件。 云控制器管理器允许您链接集群到云提供商的应用编程接口中, 并把和该云平台交互的组件与只和您的集群交互的组件分离开。
cloud-controller-manager 仅运行特定于云平台的控制回路。 如果你在自己的环境中运行 Kubernetes,或者在本地计算机中运行学习环境, 所部署的环境中不需要云控制器管理器。
与 kube-controller-manager 类似,cloud-controller-manager 将若干逻辑上独立的 控制回路组合到同一个可执行文件中,供你以同一进程的方式运行。 你可以对其执行水平扩容(运行不止一个副本)以提升性能或者增强容错能力。
下面的控制器都包含对云平台驱动的依赖:
- 节点控制器(Node Controller): 用于在节点终止响应后检查云提供商以确定节点是否已被删除
- 路由控制器(Route Controller): 用于在底层云基础架构中设置路由
- 服务控制器(Service Controller): 用于创建、更新和删除云提供商负载均衡器
(2)Node 组件
节点组件在每个节点上运行,维护运行的 Pod 并提供 Kubernetes 运行环境。
kubelet
一个在集群中每个节点(node)上运行的代理。 它保证容器(containers)都 运行在 Pod 中。
kubelet 接收一组通过各类机制提供给它的 PodSpecs,确保这些 PodSpecs 中描述的容器处于运行状态且健康。 kubelet 不会管理不是由 Kubernetes 创建的容器。
kube-proxy
kube-proxy 是集群中每个节点上运行的网络代理, 实现 Kubernetes 服务(Service) 概念的一部分。
kube-proxy 维护节点上的网络规则。这些网络规则允许从集群内部或外部的网络会话与 Pod 进行网络通信。
如果操作系统提供了数据包过滤层并可用的话,kube-proxy 会通过它来实现网络规则。否则, kube-proxy 仅转发流量本身。
二、常用命令
1、节点
(1)查看所有节点
kubectl get nodes(2)查看节点健康状态
kubectl get cs2、Pod
(1)查看pod列表
查看所有 pod ,不加 -A 默认只查看 default 命名空间的 pod
kubectl get pods -A查看指定命名空间的 pod
kubectl get pods -n 命名空间 pod名查看pod 所属节点、ip等
kubectl get pod -owide查看服务的详细信息,显示了服务名称,类型,集群ip,端口,时间等信息
kubectl get svckubectl get svc -n kube-system查看目前所有的replica set,显示了所有的pod的副本数,以及他们的可用数量以及状态等信息
kubectl get rs查看已经部署了的所有应用,可以看到容器,以及容器所用的镜像,标签等信息
kubectl get deploy -o widekubectl get deployments -o wide(2)查看 pod 日志
查看指定 pod 的日志 -f 为追踪日志更新
kubectl logs -f -n 命名空间 pod名- -f:可选,日志追踪,类似
tail -f - -n:可选,命名空间,不写默认只查 default 命名空间的pod
(3)查看 pod 描述
查看 pods 详情
kubectl describe pods -n 命名空间 pod名(4)进入 Pod
kubectl exec -it -n 命名空间 pod名 -- /bin/bashexit 命令退出 pod
(5)删除 Pod
kubectl delete pods pod名 --grace-period=0 --force3、配置文件
(1)应用配置文件
根据配置文件,给集群创建资源
kubectl apply -f xxxx.yaml(2)删除配置文件相关资源
kubectl delete -f xxxx.yaml三、命令大全

1、基础命令
(1)create
create 命令:根据文件或者输入来创建资源
创建Deployment和Service资源
kubectl create -f demo-deployment.yaml
kubectl create -f demo-service.yaml(2)delete
delete 命令:删除资源
根据yaml文件删除对应的资源,但是yaml文件并不会被删除,这样更加高效
kubectl delete -f demo-deployment.yaml
kubectl delete -f demo-service.yaml也可以通过具体的资源名称来进行删除,使用这个删除资源,同时删除deployment和service资源
kubectl delete 具体的资源名称(3)get
get 命令 :获得资源信息
查看所有的资源信息
kubectl get all
kubectl get --all-namespaces查看pod列表
# 查看pod列表
kubectl get pod
# 显示pod节点的标签信息
kubectl get pod --show-labels
# 根据指定标签匹配到具体的pod
kubectl get pods -l app=example
# 查看pod详细信息,也就是可以查看pod具体运行在哪个节点上(ip地址信息)
kubectl get pod -o wide
# 查看所有pod所属的命名空间
kubectl get pod --all-namespaces
# 查看所有pod所属的命名空间并且查看都在哪些节点上运行
kubectl get pod --all-namespaces -o wide查看node节点列表
# 查看node节点列表
kubectl get node
# 显示node节点的标签信息
kubectl get node --show-labels查看服务的详细信息,显示了服务名称,类型,集群ip,端口,时间等信息
kubectl get svc
kubectl get svc -n kube-system查看命名空间
kubectl get ns
kubectl get namespaces查看目前所有的replica set,显示了所有的pod的副本数,以及他们的可用数量以及状态等信息
kubectl get rs查看已经部署了的所有应用,可以看到容器,以及容器所用的镜像,标签等信息
kubectl get deploy -o wide
kubectl get deployments -o wide(4)run
run 命令:在集群中创建并运行一个或多个容器镜像。
语法:run NAME –image=image [–env=”key=value”] [–port=port] [–replicas=replicas] [–dry-run=bool] [–overrides=inline-json] [–command] – [COMMAND] [args…]
# 示例,运行一个名称为nginx,副本数为3,标签为app=example,镜像为nginx:1.10,端口为80的容器实例
kubectl run nginx --replicas=3 --labels="app=example" --image=nginx:1.10 --port=80
# 示例,运行一个名称为nginx,副本数为3,标签为app=example,镜像为nginx:1.10,端口为80的容器实例,并绑定到k8s-node1上$ kubectl run nginx --image=nginx:1.10 --replicas=3 --labels="app=example" --port=80 --overrides='{"apiVersion":"apps/v1","spec":{"template":{"spec":{"nodeSelector":{"kubernetes.io/hostname":"k8s-node1"}}}}}'更详细用法参见:http://docs.kubernetes.org.cn/468.html
(5)expose
expose 命令:创建一个service服务,并且暴露端口让外部可以访问
# 创建一个nginx服务并且暴露端口让外界可以访问
kubectl expose deployment nginx --port=88 --type=NodePort --target-port=80 --name=nginx-service更多expose详细用法参见:http://docs.kubernetes.org.cn/475.html
(6)set
set 命令:配置应用的一些特定资源,也可以修改应用已有的资源
使用
kubectl set --help查看,它的子命令,env,image,resources,selector,serviceaccount,subject。
语法:resources (-f FILENAME | TYPE NAME) ([–limits=LIMITS & –requests=REQUESTS]
set 命令详情参见:http://docs.kubernetes.org.cn/669.html
kubectl set resources
这个命令用于设置资源的一些范围限制。
资源对象中的Pod可以指定计算资源需求(CPU-单位m、内存-单位Mi),即使用的最小资源请求(Requests),限制(Limits)的最大资源需求,Pod将保证使用在设置的资源数量范围。
对于每个Pod资源,如果指定了Limits(限制)值,并省略了Requests(请求),则Requests默认为Limits的值。
可用资源对象包括(支持大小写):replicationcontroller、deployment、daemonset、job、replicaset。
# 将deployment的nginx容器cpu限制为“200m”,将内存设置为“512Mi”
kubectl set resources deployment nginx -c=nginx --limits=cpu=200m,memory=512Mi
# 设置所有nginx容器中 Requests和Limits
kubectl set resources deployment nginx --limits=cpu=200m,memory=512Mi --requests=cpu=100m,memory=256Mi
# 删除nginx中容器的计算资源值
kubectl set resources deployment nginx --limits=cpu=0,memory=0 --requests=cpu=0,memory=0kubectl set selector
设置资源的 selector(选择器)。如果在调用”set selector”命令之前已经存在选择器,则新创建的选择器将覆盖原来的选择器。
selector必须以字母或数字开头,最多包含63个字符,可使用:字母、数字、连字符” - “ 、点”.”和下划线” _ “。如果指定了–resource-version,则更新将使用此资源版本,否则将使用现有的资源版本。
注意:目前selector命令只能用于Service对象。
语法:selector (-f FILENAME | TYPE NAME) EXPRESSIONS [–resource-version=version]
kubectl set image
用于更新现有资源的容器镜像。
可用资源对象包括:pod (po)、replicationcontroller (rc)、deployment (deploy)、daemonset (ds)、job、replicaset (rs)。
语法:image (-f FILENAME | TYPE NAME) CONTAINER_NAME_1=CONTAINER_IMAGE_1 … CONTAINER_NAME_N=CONTAINER_IMAGE_N
# 将deployment中的nginx容器镜像设置为“nginx:1.9.1”
kubectl set image deployment/nginx busybox=busybox nginx=nginx:1.9.1
# 所有deployment和rc的nginx容器镜像更新为“nginx:1.9.1”
kubectl set image deployments,rc nginx=nginx:1.9.1 --all
# 将daemonset abc的所有容器镜像更新为“nginx:1.9.1”
kubectl set image daemonset abc *=nginx:1.9.1
# 从本地文件中更新nginx容器镜像
kubectl set image -f path/to/file.yaml nginx=nginx:1.9.1 --local -o yaml(7)explain
explain 命令:用于显示资源文档信息
kubectl explain rs(8)edit
edit 命令: 用于编辑资源信息
# 编辑Deployment nginx的一些信息
kubectl edit deployment nginx
# 编辑service类型的nginx的一些信息
kubectl edit service/nginx2、设置命令
(1)label
label命令: 用于更新(增加、修改或删除)资源上的 label(标签)
label必须以字母或数字开头,可以使用字母、数字、连字符、点和下划线,最长63个字符。- 如果
--overwrite为true,则可以覆盖已有的label,否则尝试覆盖label将会报错。 - 如果指定了
--resource-version,则更新将使用此资源版本,否则将使用现有的资源版本。
语法:label [–overwrite] (-f FILENAME | TYPE NAME) KEY_1=VAL_1 … KEY_N=VAL_N [–resource-version=version]
# 给名为foo的Pod添加label unhealthy=true
kubectl label pods foo unhealthy=true
# 给名为foo的Pod修改label 为 'status' / value 'unhealthy',且覆盖现有的value
kubectl label --overwrite pods foo status=unhealthy
# 给 namespace 中的所有 pod 添加 label
kubectl label pods --all status=unhealthy
# 仅当resource-version=1时才更新 名为foo的Pod上的label
kubectl label pods foo status=unhealthy --resource-version=1
# 删除名为“bar”的label 。(使用“ - ”减号相连)
kubectl label pods foo bar-(2)annotate
annotate命令:更新一个或多个资源的Annotations信息。也就是注解信息,可以方便的查看做了哪些操作。
Annotations由key/value组成。Annotations的目的是存储辅助数据,特别是通过工具和系统扩展操作的数据,更多介绍在这里。- 如果
--overwrite为true,现有的annotations可以被覆盖,否则试图覆盖annotations将会报错。 - 如果设置了
--resource-version,则更新将使用此resource version,否则将使用原有的resource version。
语法:annotate [–overwrite] (-f FILENAME | TYPE NAME) KEY_1=VAL_1 … KEY_N=VAL_N [–resource-version=version]
# 更新Pod“foo”,设置annotation “description”的value “my frontend”,如果同一个annotation多次设置,则只使用最后设置的value值
kubectl annotate pods foo description='my frontend'
# 根据“pod.json”中的type和name更新pod的annotation
kubectl annotate -f pod.json description='my frontend'
# 更新Pod"foo",设置annotation“description”的value“my frontend running nginx”,覆盖现有的值
kubectl annotate --overwrite pods foo description='my frontend running nginx'
# 更新 namespace中的所有pod
kubectl annotate pods --all description='my frontend running nginx'
# 只有当resource-version为1时,才更新pod 'foo'
kubectl annotate pods foo description='my frontend running nginx' --resource-version=1
# 通过删除名为“description”的annotations来更新pod 'foo'。
# 不需要 -overwrite flag。
kubectl annotate pods foo description-(3)completion
completion命令:用于设置 kubectl 命令自动补全
# 在 bash 中设置当前 shell 的自动补全,要先安装 bash-completion 包
source <(kubectl completion bash) # 在您的 bash shell 中永久的添加自动补全 echo "source <(kubectl bash)">> ~/.bashrc# 在 zsh 中设置当前 shell 的自动补全
source <(kubectl completion zsh) # 在您的 zsh shell 中永久的添加自动补全 echo "if [ $commands[kubectl] ]; then source <(kubectl zsh); fi">> ~/.zshrc3、部署命令
kubectl 部署命令:rollout,rolling-update,scale,autoscale
(1)rollout
rollout 命令: 用于对资源进行管理
可用资源包括:deployments,daemonsets。
子命令:
history(查看历史版本)pause(暂停资源)resume(恢复暂停资源)status(查看资源状态)undo(回滚版本)
# 语法
kubectl rollout SUBCOMMAND
# 回滚到之前的deployment
kubectl rollout undo deployment/abc
# 查看daemonet的状态
kubectl rollout status daemonset/foo(2)rolling-update
rolling-update命令: 执行指定ReplicationController的滚动更新。
该命令创建了一个新的RC, 然后一次更新一个pod方式逐步使用新的PodTemplate,最终实现Pod滚动更新,new-controller.json需要与之前RC在相同的namespace下。
语法:rolling-update OLD_CONTROLLER_NAME ([NEW_CONTROLLER_NAME] –image=NEW_CONTAINER_IMAGE | -f NEW_CONTROLLER_SPEC)
# 使用frontend-v2.json中的新RC数据更新frontend-v1的pod
kubectl rolling-update frontend-v1 -f frontend-v2.json
# 使用JSON数据更新frontend-v1的pod
cat frontend-v2.json | kubectl rolling-update frontend-v1 -f -
# 其他的一些滚动更新
kubectl rolling-update frontend-v1 frontend-v2 --image=image:v2
kubectl rolling-update frontend --image=image:v2
kubectl rolling-update frontend-v1 frontend-v2 --rollback(3)scale
scale命令:扩容或缩容 Deployment、ReplicaSet、Replication Controller或 Job 中Pod数量
scale也可以指定多个前提条件,如:当前副本数量或 --resource-version ,进行伸缩比例设置前,系统会先验证前提条件是否成立。这个就是弹性伸缩策略。
语法:kubectl scale [–resource-version=version] [–current-replicas=count] –replicas=COUNT (-f FILENAME | TYPE NAME)
# 将名为foo中的pod副本数设置为3。
kubectl scale --replicas=3 rs/foo
kubectl scale deploy/nginx --replicas=30
# 将由“foo.yaml”配置文件中指定的资源对象和名称标识的Pod资源副本设为3
kubectl scale --replicas=3 -f foo.yaml
# 如果当前副本数为2,则将其扩展至3。
kubectl scale --current-replicas=2 --replicas=3 deployment/mysql
# 设置多个RC中Pod副本数量
kubectl scale --replicas=5 rc/foo rc/bar rc/baz(4)autoscale
autoscale命令:这个比scale更加强大,也是弹性伸缩策略 ,它是根据流量的多少来自动进行扩展或者缩容。
指定Deployment、ReplicaSet或ReplicationController,并创建已经定义好资源的自动伸缩器。使用自动伸缩器可以根据需要自动增加或减少系统中部署的pod数量。
语法:kubectl autoscale (-f FILENAME | TYPE NAME | TYPE/NAME) [–min=MINPODS] –max=MAXPODS [–cpu-percent=CPU] [flags]
# 使用 Deployment “foo”设定,使用默认的自动伸缩策略,指定目标CPU使用率,使其Pod数量在2到10之间
kubectl autoscale deployment foo --min=2 --max=10
# 使用RC“foo”设定,使其Pod的数量介于1和5之间,CPU使用率维持在80%
kubectl autoscale rc foo --max=5 --cpu-percent=804、集群管理命令
集群管理命令:certificate,cluster-info,top,cordon,uncordon,drain,taint
(1)certificate
certificate命令:用于证书资源管理,授权等
# 例如,当有node节点要向master请求,那么是需要master节点授权的
kubectl certificate approve node-csr-81F5uBehyEyLWco5qavBsxc1GzFcZk3aFM3XW5rT3mw node-csr-Ed0kbFhc_q7qx14H3QpqLIUs0uKo036O2SnFpIheM18(2)cluster-info
cluster-info 命令:显示集群信息
kubectl cluster-info(3)top
top 命令:用于查看资源的cpu,内存磁盘等资源的使用率
# 以前需要heapster,后替换为metrics-server
kubectl top pod --all-namespaces(4)其他
cordon命令:用于标记某个节点不可调度
uncordon命令:用于标签节点可以调度
drain命令:用于在维护期间排除节点。
taint命令:用于给某个Node节点设置污点
5、集群故障排查和调试命令
集群故障排查和调试命令:describe,logs,exec,attach,port-foward,proxy,cp,auth
(1)describe
describe命令:显示特定资源的详细信息
# 查看my-nginx pod的详细状态
kubectl describe po my-nginx(2)logs
logs命令:用于在一个pod中打印一个容器的日志,如果pod中只有一个容器,可以省略容器名
语法:kubectl logs [-f] [-p] POD [-c CONTAINER]
# 返回仅包含一个容器的pod nginx的日志快照
kubectl logs nginx
# 返回pod ruby中已经停止的容器web-1的日志快照
kubectl logs -p -c ruby web-1
# 持续输出pod ruby中的容器web-1的日志
kubectl logs -f -c ruby web-1
# 仅输出pod nginx中最近的20条日志
kubectl logs --tail=20 nginx
# 输出pod nginx中最近一小时内产生的所有日志
kubectl logs --since=1h nginx参数选项:
- -c, –container=””: 容器名。
- -f, –follow[=false]: 指定是否持续输出日志(实时日志)。
- –interactive[=true]: 如果为true,当需要时提示用户进行输入。默认为true。
- –limit-bytes=0: 输出日志的最大字节数。默认无限制。
- -p, –previous[=false]: 如果为true,输出pod中曾经运行过,但目前已终止的容器的日志。
- –since=0: 仅返回相对时间范围,如5s、2m或3h,之内的日志。默认返回所有日志。只能同时使用since和since-time中的一种。
- –since-time=””: 仅返回指定时间(RFC3339格式)之后的日志。默认返回所有日志。只能同时使用since和since-time中的一种。
- –tail=-1: 要显示的最新的日志条数。默认为-1,显示所有的日志。
- –timestamps[=false]: 在日志中包含时间戳。
(3)exec
exec命令:进入容器进行交互,在容器中执行命令
语法:kubectl exec POD [-c CONTAINER] – COMMAND [args…]
命令选项:
- -c, –container=””: 容器名。如果未指定,使用pod中的一个容器。
- -p, –pod=””: Pod名。
- -i, –stdin[=false]: 将控制台输入发送到容器。
- -t, –tty[=false]: 将标准输入控制台作为容器的控制台输入。
# 进入nginx容器,执行一些命令操作
kubectl exec -it nginx-deployment-58d6d6ccb8-lc5fp bash(4)attach
attach命令:连接到一个正在运行的容器。
语法:kubectl attach POD -c CONTAINER
参数选项:
- -c, –container=””: 容器名。如果省略,则默认选择第一个 pod。
- -i, –stdin[=false]: 将控制台输入发送到容器。
- -t, –tty[=false]: 将标准输入控制台作为容器的控制台输入。
# 获取正在运行中的pod 123456-7890的输出,默认连接到第一个容器
kubectl attach 123456-7890
# 获取pod 123456-7890中ruby-container的输出
kubectl attach 123456-7890 -c ruby-container
# 切换到终端模式,将控制台输入发送到pod 123456-7890的ruby-container的“bash”命令,并将其输出到控制台/
# 错误控制台的信息发送回客户端。
kubectl attach 123456-7890 -c ruby-container -i -t(5)cp
cp命令:拷贝文件或者目录到pod容器中
用于pod和外部的文件交换,类似于docker 的cp,就是将容器中的内容和外部的内容进行交换。
6、其他命令
其他命令:api-servions,config,help,plugin,version
(1)api-servions
api-servions命令:打印受支持的api版本信息
# 打印当前集群支持的api版本
kubectl api-versions(2)help
help命令:用于查看命令帮助
# 显示全部的命令帮助提示
$ kubectl --help
# 具体的子命令帮助,例如
$ kubectl create --help(3)config
config 命令: 用于修改kubeconfig配置文件(用于访问api,例如配置认证信息)
设置 kubectl 与哪个 Kubernetes 集群进行通信并修改配置信息。查看 使用 kubeconfig 跨集群授权访问 文档获取详情配置文件信息。
# 显示合并的 kubeconfig 配置
kubectl config view
# 同时使用多个 kubeconfig 文件并查看合并的配置
KUBECONFIG=~/.kube/config:~/.kube/kubconfig2 kubectl config view
# 获取 e2e 用户的密码
kubectl config view -o jsonpath='{.users[?(@.name == "e2e")].user.password}'
# 展示当前所处的上下文
kubectl config current-context
# 设置默认的上下文为 my-cluster-name
kubectl config use-context my-cluster-name
# 添加新的集群配置到 kubeconf 中,使用 basic auth 进行鉴权
kubectl config set-credentials kubeuser/foo.kubernetes.com --username=kubeuser --password=kubepassword
# 使用特定的用户名和命名空间设置上下文。
kubectl config set-context gce --user=cluster-admin --namespace=foo \
&& kubectl config use-context gce(4)version
version 命令:打印客户端和服务端版本信息
# 打印客户端和服务端版本信息
kubectl version(5)plugin
plugin 命令:运行一个命令行插件
7、高级命令
高级命令:apply,patch,replace,convert
(1)apply
apply命令:通过文件名或者标准输入对资源应用配置
通过文件名或控制台输入,对资源进行配置。如果资源不存在,将会新建一个。可以使用 JSON 或者 YAML格式。
语法:kubectl apply -f FILENAME
# 将pod.json中的配置应用到pod
kubectl apply -f ./pod.json
# 将控制台输入的JSON配置应用到Pod
cat pod.json | kubectl apply -f -参数选项:
- -f, –filename=[]: 包含配置信息的文件名,目录名或者URL。
- –include-extended-apis[=true]: If true, include definitions of new APIs via calls to the API server. [default true]
- -o, –output=””: 输出模式。”-o name”为快捷输出(资源/name).
- –record[=false]: 在资源注释中记录当前 kubectl 命令。
- -R, –recursive[=false]: Process the directory used in -f, –filename recursively. Useful when you want to manage related manifests organized within the same directory.
- –schema-cache-dir=”~/.kube/schema”: 非空则将API schema缓存为指定文件,默认缓存到’$HOME/.kube/schema’
- –validate[=true]: 如果为true,在发送到服务端前先使用schema来验证输入。
(2)patch
patch命令:使用补丁修改,更新资源的字段,也就是修改资源的部分内容
语法:kubectl patch (-f FILENAME | TYPE NAME) -p PATCH
# Partially update a node using strategic merge patch
kubectl patch node k8s-node-1 -p '{"spec":{"unschedulable":true}}'
# Update a container's image; spec.containers[*].name is required because it's a merge key
kubectl patch pod valid-pod -p '{"spec":{"containers":[{"name":"kubernetes-serve-hostname","image":"new image"}]}}'(3)replace
replace命令:通过文件或者标准输入替换原有资源
语法:kubectl replace -f FILENAME
# Replace a pod using the data in pod.json.
kubectl replace -f ./pod.json
# Replace a pod based on the JSON passed into stdin.
cat pod.json | kubectl replace -f -
# Update a single-container pod's image version (tag) to v4
$ kubectl get pod mypod -o yaml | sed 's/\(image: myimage\):.*$/\1:v4/' | kubectl replace -f -
# Force replace, delete and then re-create the resource
kubectl replace --force -f ./pod.json(4)convert
convert命令:不同的版本之间转换配置文件
语法:kubectl convert -f FILENAME
# Convert 'pod.yaml' to latest version and print to stdout.
kubectl convert -f pod.yaml
# Convert the live state of the resource specified by 'pod.yaml' to the latest version
# and print to stdout in json format.
kubectl convert -f pod.yaml --local -o json
# Convert all files under current directory to latest version and create them all.
kubectl convert -f . | kubectl create -f -8、格式化输出
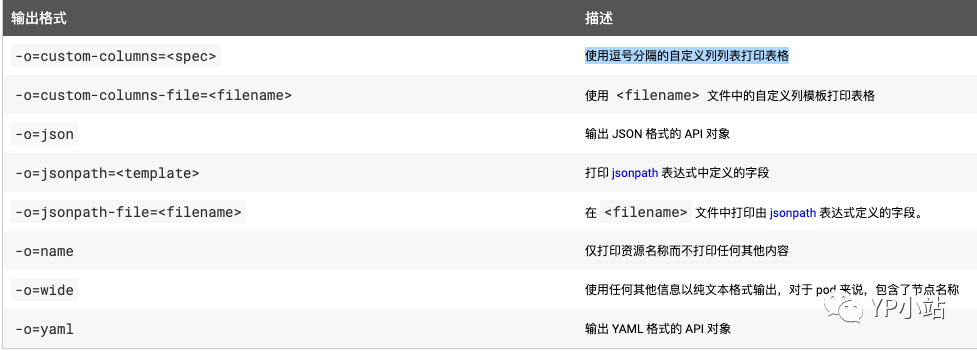
要以特定格式将详细信息输出到终端窗口,可以将 -o 或 --output 参数添加到支持的 kubectl 命令。
9、Kubectl 日志输出详细程度和调试
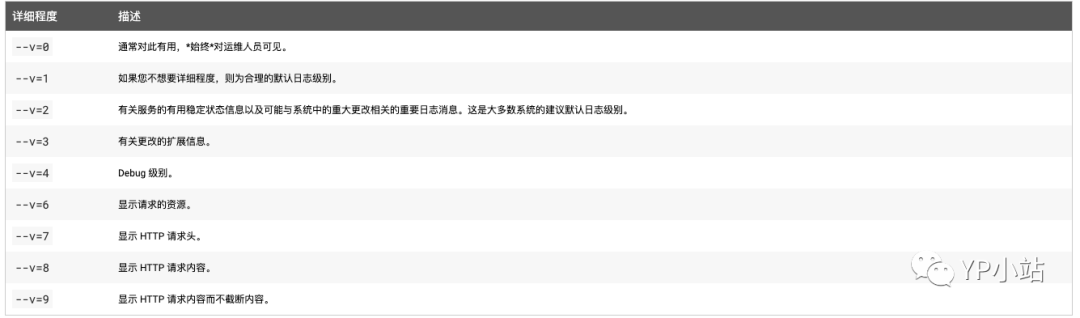
Kubectl 日志输出详细程度是通过 -v 或者 --v 来控制的,参数后跟了一个数字表示日志的级别。Kubernetes 通用的日志习惯和相关的日志级别在 这里 有相应的描述。
10、create和apply区别
kubectl create命令可创建新资源。 因此,如果再次运行该命令,则会抛出错误,因为资源名称在名称空间中应该是唯一的。
kubectl apply命令将配置应用于资源。 如果资源不在那里,那么它将被创建。 kubectl apply命令可以第二次运行,因为它只是应用如下所示的配置。 在这种情况下,配置没有改变。 所以,pod没有改变。
四、Kubernetes搭建
1、前置环境搭建
需要安装docker
- 节点之中不可以有重复的主机名、MAC 地址或 product_uuid。请参见这里了解更多详细信息。
- 开启机器上的某些端口。请参见这里 了解更多详细信息。
- 禁用交换分区。为了保证 kubelet 正常工作, 必须 禁用交换分区。
#各个机器设置自己的主机名
hostnamectl set-hostname xxxx
# 查看主机名
hostname
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
# 将 SELinux 设置为 permissive 模式(相当于将其禁用)
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
#关闭swap
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
#允许 iptables 检查桥接流量
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sudo sysctl --system时间同步,这里注意,本地安装虚拟机的,建议每次打开虚拟机都执行一次同步时间的命令。因为本地休眠或者关机后,时间就不会更新了。
yum install ntpdate -y
ntpdate time.windows.com #每次打开虚拟机都执行一次这个2、安装kubelet、kubeadm、kubectl
添加阿里云源
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
exclude=kubelet kubeadm kubectl
EOF安装三件套
sudo yum install -y kubelet-1.20.9 kubeadm-1.20.9 kubectl-1.20.9 --disableexcludes=kubernetes设置开机自启,并启动 kubelet
sudo systemctl enable kubelet
sudo systemctl start kubeletkubelet 现在每隔几秒就会重启,因为它陷入了一个等待 kubeadm 指令的死循环
可通过下面的命令查看启动情况
sudo systemctl status kubelet3、使用kubeadm引导集群
(1)下载需要的镜像
以下命令是用于生成下载镜像的 shell 脚本文件
sudo tee ./images.sh <<-'EOF' #! bin bash images="(" kube-apiserver:v1.20.9 kube-proxy:v1.20.9 kube-controller-manager:v1.20.9 kube-scheduler:v1.20.9 coredns:1.7.0 etcd:3.4.13-0 pause:3.2 ) for imagename in ${images[@]} ; do docker pull registry.cn-hangzhou.aliyuncs.com lfy_k8s_images $imagename done eof< code>使用以下命令执行脚本
chmod +x ./images.sh && ./images.sh下载完成后使用以下命令检查镜像是否下载完成
docker images(2)自定义内网解析域名
如果是主节点没有域名需要内网解析域名,所有机器都要执行以下命令,配置 master 节点的域名解析,ip 为 master 的 ip
vi /etc/hosts192.168.0.200 k8s-master01
192.168.0.201 k8s-node01
192.168.0.202 k8s-node02在非主节点上通过以下命令检查连通性
ping k8s-master01(3)部署主节点
注意:所有网络范围不重叠
kubeadm init \
--apiserver-advertise-address=192.168.0.200 \
--control-plane-endpoint=k8s-master01 \
--image-repository registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images \
--kubernetes-version v1.20.9 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=10.244.0.0/16--apiserver-advertise-address:apiserver的地址,修改为上面第二步的 master 的 ip--control-plane-endpoint:修改为上面第二步的 master 的域名--pod-network-cidr:pod 的网络ip范围
如果使用 Flannel 建议这个配置 --pod-network-cidr=10.244.0.0/16,这样到时候就不用改Flannel的配置文件了
执行完以上命令后需要保存结果信息
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join cluster-endpoint:6443 --token jxz09o.pn5sxv0u47ir2ma8 \
--discovery-token-ca-cert-hash sha256:7cc8b7d1f5e18466f25757b12ee1aeee5374d07d1bd205240a7f67a33f68f82c \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join cluster-endpoint:6443 --token jxz09o.pn5sxv0u47ir2ma8 \
--discovery-token-ca-cert-hash sha256:7cc8b7d1f5e18466f25757b12ee1aeee5374d07d1bd205240a7f67a33f68f82cmaster节点init后后出现一个node用来join到master的命令,里面包含了token等信息,但是这个有效期只有24小时,需要重新获取重新输入以下命令
kubeadm token create --print-join-command根据结果提示执行命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config执行后可通过以下命令查看节点信息(不过此时只有一个主节点)
kubectl get nodes(4)部署node节点
将node节点join到master节点,复制上面master在init时打印出来的join命令
kubeadm join k8s-master01:6443 --token tdw2gr.elas5axpj496jc86 \
--discovery-token-ca-cert-hash sha256:52d895dceb9505e03667b968446e3c5d724e67ea4993bdebd47735c93170dae3上面的token只有24小时的有效时间,如果后面节点超过了token有效期想要加入master,需要重新获取token。
查看node节点有无加入到master节点,下面命令在master机器执行
kubectl get nodes这个命令会看到node节点已加入到master节点,但是他的状态时NotReady,下面会安装网络插件。
如果显示下面这样的,需要将 主节点的 /etc/kubernetes/admin.conf 复制到从节点
[root@server2 kubernetes]# kubectl get nodes
W0802 15:59:08.439541 16061 loader.go:223] Config not found: /etc/kubernetes/admin.conf
The connection to the server localhost:8080 was refused - did you specify the right host or port?4、安装网络插件(master)
(1)Flannel
直接下载并安装(因为要修改配置,不推荐)
kubectl apply -f https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml先下载配置文件在安装
curl https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml -O初始化master节点时,如果指定了 –pod-network-cidr=192.168.0.0/16
那么,kube-flannel.yml 中该部分网段也要进行对应,默认是10.244.0.0/16
vi kube-flannel.yml
net-conf.json: |
{
"Network": "192.168.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
安装
kubectl apply -f kube-flannel.yml验证
kubectl get nodes
kubectl get cs
kubectl cluster-info注意:如果重装 flannel 需要删除他创建的网卡后,在重新安装
sudo ifconfig flannel.1 down
sudo ip link delete flannel.15、部署dashboard(可选)
(1)安装
kubernetes官方提供的可视化界面
https://github.com/kubernetes/dashboard
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.3.1/aio/deploy/recommended.yaml(2)设置访问端口
(操作方式和 vi 一样)
kubectl edit svc kubernetes-dashboard -n kubernetes-dashboardtype: ClusterIP 改为 type: NodePort
找到端口,在安全组放行
[root@server1 k8s]# kubectl get svc -A |grep kubernetes-dashboard
kubernetes-dashboard dashboard-metrics-scraper ClusterIP 10.96.203.210 8000/TCP 2m5s
kubernetes-dashboard kubernetes-dashboard NodePort 10.96.203.213 443:31014/TCP 2m5s
访问: https://集群任意IP:端口 https://139.198.165.238:31014
(3)连接不安全无法访问
在浏览器页面上,直接键盘输入 :thisisunsafe
不论是chrome还是edge,都可以解决。
(4)创建访问账号
#创建访问账号,准备一个yaml文件; vi dash.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboardkubectl apply -f dash.yaml(5)令牌访问
获取访问令牌
kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}") -o go-template="{{.data.token | base64decode}}"v2.6.0使用下面命令获取token
kubectl -n kubernetes-dashboard create token admin-user6、kubectl命令自动补全(可选)
https://kubernetes.io/zh-cn/docs/tasks/tools/install-kubectl-linux/#enable-shell-autocompletion
yum install -y bash-completion
source /usr/share/bash-completion/bash_completion
source <(kubectl completion bash)
echo “source <(kubectl completion bash)” >> ~/.bashrc
source /usr/share/bash-completion/bash_completion
source <(kubectl completion bash)问题
(1)kube-system coredns状态异常
[root@server1 k8s]# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-flannel kube-flannel-ds-kh4dc 0/1 Error 1 14s
kube-flannel kube-flannel-ds-swhjd 0/1 CrashLoopBackOff 1 14s
kube-flannel kube-flannel-ds-vlbmm 0/1 CrashLoopBackOff 1 14s
kube-system coredns-5897cd56c4-rmgjv 0/1 ContainerCreating 0 6h52m
kube-system coredns-5897cd56c4-s6zhv 0/1 ContainerCreating 0 6h52m
kube-system etcd-server1 1/1 Running 0 6h52m
kube-system kube-apiserver-server1 1/1 Running 0 6h52m
kube-system kube-controller-manager-server1 1/1 Running 0 6h52m
kube-system kube-proxy-tbmpp 1/1 Running 0 6h35m
kube-system kube-proxy-wfvnx 1/1 Running 0 6h52m
kube-system kube-proxy-xf9g6 1/1 Running 0 6h43m
kube-system kube-scheduler-server1 1/1 Running 0 6h52m查看错误详情
kubectl describe pods -n kube-system coredns-5897cd56c4-s6zhv查看下面的日志
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 16m (x371 over 6h29m) default-scheduler 0/3 nodes are available: 3 node(s) had taint {node.kubernetes.io/not-ready: }, that the pod didn't tolerate.
Warning FailedCreatePodSandBox 12m kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed to set up sandbox container "ff501bd62c740b9043e4ec8e753955197b396b7754646292f870f4b9f471ce5d" network for pod "coredns-5897cd56c4-s6zhv": networkPlugin cni failed to set up pod "coredns-5897cd56c4-s6zhv_kube-system" network: loadFlannelSubnetEnv failed: open /run/flannel/subnet.env: no such file or directory重点
network: loadFlannelSubnetEnv failed: open /run/flannel/subnet.env: no such file or directory不存在该文件,那就创建
vi /run/flannel/subnet.env文件内容
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.0.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true(2)node节点异常
从节点出现以下错误
[root@server2 ~]# kubectl get node
The connection to the server localhost:8080 was refused - did you specify the right host or port?将主节点的 /etc/kubernetes/admin.conf 文件拷贝到从节点的相同路径即可
从节点执行以下命令
echo $KUBECONFIG
export KUBECONFIG=/etc/kubernetes/admin.conf
echo $KUBECONFIG或
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile(3)flannel状态异常
[root@server1 k8s]# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-flannel kube-flannel-ds-n9ts2 0/1 CrashLoopBackOff 1 14s
kube-flannel kube-flannel-ds-pbbmg 0/1 CrashLoopBackOff 1 14s
kube-flannel kube-flannel-ds-xlzmz 0/1 CrashLoopBackOff 1 14s查看日志
kubectl logs -n kube-flannel kube-flannel-ds-xlzmzE0802 03:14:00.816765 1 main.go:335] Error registering network: failed to acquire lease: subnet "10.244.0.0/16" specified in the flannel net config doesn't contain "192.168.1.0/24" PodCIDR of the "server2" node
I0802 03:14:00.816917 1 main.go:523] Stopping shutdownHandler...
W0802 03:14:00.817134 1 reflector.go:347] github.com/flannel-io/flannel/pkg/subnet/kube/kube.go:490: watch of *v1.Node ended with: an error on the server ("unable to decode an event from the watch stream: context canceled") has prevented the request from succeeding原因:初始化master节点时,指定了 –pod-network-cidr=192.168.0.0/16
那么,kube-flannel.yml 中该部分网段也要进行对应,默认是10.244.0.0/16
vi kube-flannel.yml
net-conf.json: |
{
"Network": "192.168.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
(4)集群健康状态异常
[root@server1 k8s]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
etcd-0 Healthy {"health":"true"} 解决办法:
cd /etc/kubernetes/manifests/将该目录下的 kube-controller-manager.yaml 和 kube-scheduler.yaml 的 - --port=0 注释即可
出现这种情况是kube-controller-manager.yaml和kube-scheduler.yaml设置的默认端口是0,在配置文件中注释掉“- --port=0”并重启服务就可以了。(每台master节点都要执行操作)重启服务
systemctl restart kubelet.service正常状态如下:
[root@server1 manifests]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"} (5)无法创建pod网络
pod 无法创建,通过一下命令获取错误信息
kubectl describe pods -n 命名空间 pod名failed to delegate add: failed to set bridge addr: "cni0" already has an IP address different from 10.244.1.1/24删除错误网卡,k8s自己会重建
ifconfig cni0 down
ip link delete cni0(6)内存泄漏
https://cloud.tencent.com/developer/article/1739289
kubectl describe pods -n 命名空间 pod名当出现下面报错时,检查是否是内存泄漏
cannot allocate memory: unknown执行以下命令
cat /sys/fs/cgroup/memory/kubepods/memory.kmem.slabinfo如果输出类似下面的,则出现了内存泄漏
slabinfo - version: 2.1
# name : tunables : slabdata 一句话总结:
- cgroup 的 kmem account 特性在 3.x 内核上有内存泄露问题,如果开启了 kmem account 特性 会导致可分配内存越来越少,直到无法创建新 pod 或节点异常。
几点解释:
- 1、kmem account 是cgroup 的一个扩展,全称CONFIG_MEMCG_KMEM,属于机器默认配置,本身没啥问题,只是该特性在 3.10 的内核上存在漏洞有内存泄露问题,4.x的内核修复了这个问题。centos8能避免
- 2、因为 kmem account 是 cgroup 的扩展能力,因此runc、docker、k8s 层面也进行了该功能的支持,即默认都打开了kmem 属性。
- 3、因为3.10 的内核已经明确提示 kmem 是实验性质,我们仍然使用该特性,所以这其实不算内核的问题,是 k8s 兼容问题。
解决方式
修改虚机启动的引导项 grub 中的 cgroup.memory=nokmem,让机器启动时直接禁用 cgroup的 kmem 属性
# 修改/etc/default/grub ,在GRUB_CMDLINE_LINUX最后添加cgroup.memory=nokmem
GRUB_CMDLINE_LINUX="crashkernel=auto net.ifnames=0 biosdevname=0 intel_pstate=disable cgroup.memory=nokmem"
# 生成配置:
/usr/sbin/grub2-mkconfig -o /boot/grub2/grub.cfg
# 重启机器:
reboot
# 验证: 无输出即可。
cat /sys/fs/cgroup/memory/kubepods/burstable/pod*/*/memory.kmem.slabinfo复制
这个方式对一些机器生效,但有些机器替换后没生效,且这个操作也需要机器重启
重置kubeadm
移除所有工作节点
kubectl delete node izwz9ac58lkokssyf8owagz所有工作节点删除工作目录,并重置kubeadm
rm -rf /etc/kubernetes/*
rm -rf ~/.kube/*
kubeadm resetMaster节点删除工作目录,并重置kubeadm
rm -rf /etc/kubernetes/*
rm -rf ~/.kube/*
rm -rf /var/lib/etcd/*
kubeadm reset -f重新init kubernetes
卸载 K8S
# 停止相关服务
systemctl stop kubelet
systemctl stop etcd
systemctl stop docker
# 卸载 k8s
kubeadm reset -f
# 清除相关目录
modprobe -r ipip
lsmod
rm -rf ~/.kube/
rm -rf /etc/kubernetes/
rm -rf /etc/systemd/system/kubelet.service.d
rm -rf /etc/systemd/system/kubelet.service
rm -rf /usr/bin/kube*
rm -rf /etc/cni
rm -rf /opt/cni
rm -rf /var/lib/etcd
rm -rf /var/etcd
# 卸载相关程序
yum -y remove kube*
#更新镜像
yum clean all
yum -y update
yum makecache五、服务部署
1、Nginx
kubectl create deployment nginx --image=nginx:1.14-alpine暴露端口
kubectl expose deployment nginx --port=80 --type=NodePort查看服务状态
kubectl get pods,svc
