一、Kafka概述
1、基本介绍
Kafka传统定义:Kafka是一个分布式的基于发布/订阅模式的消息队列(MessageQueue),主要应用于大数据实时处理领域。
Kafka最新定义:Kafka是一个开源的分布式事件流平台(Event StreamingPlatform),被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用。
传统的消息队列的主要应用场景包括:缓存消峰、解耦和异步通信。
2、消息队列两种模式
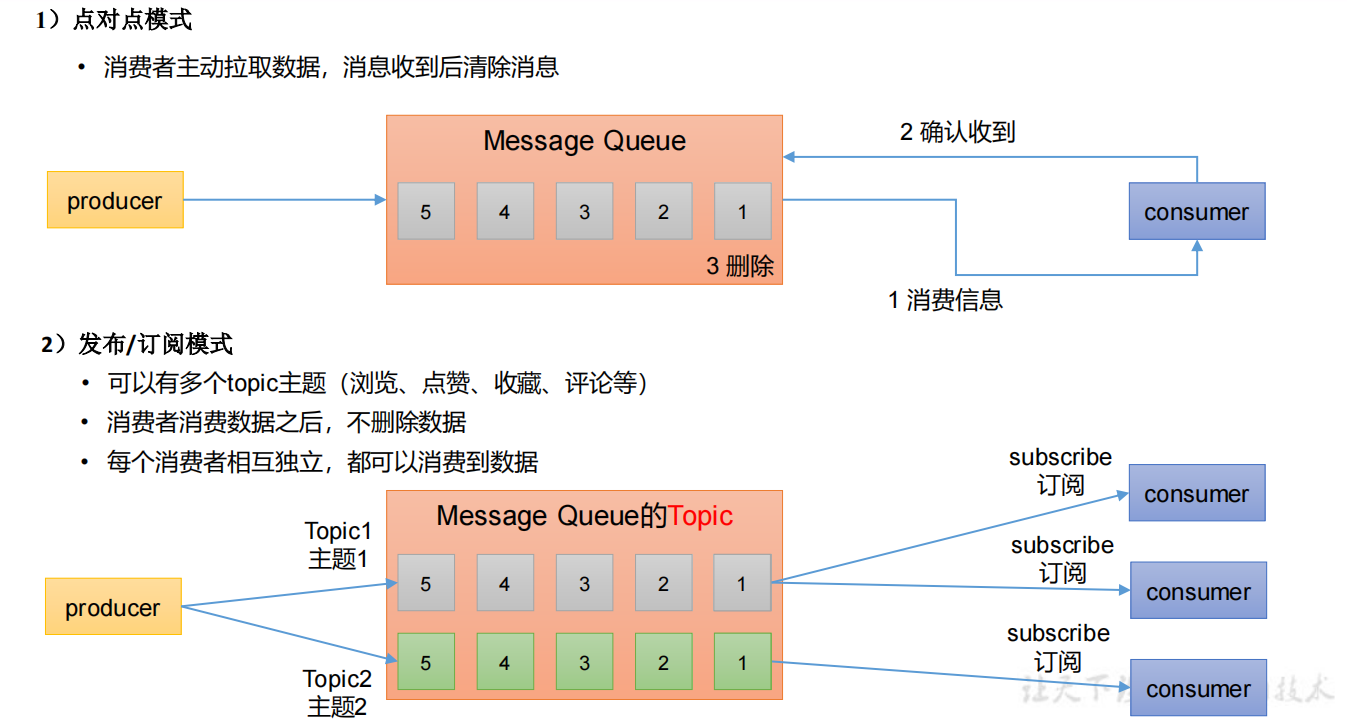
区别: 点对点消费 -> 消息只能发布到一个主题, 消费完成就删除消息,且只有一个消费者
发布订阅模式 -> 消息可以发布到多个主题, 消息一般保留七天,且有多个消费者
3、基础架构
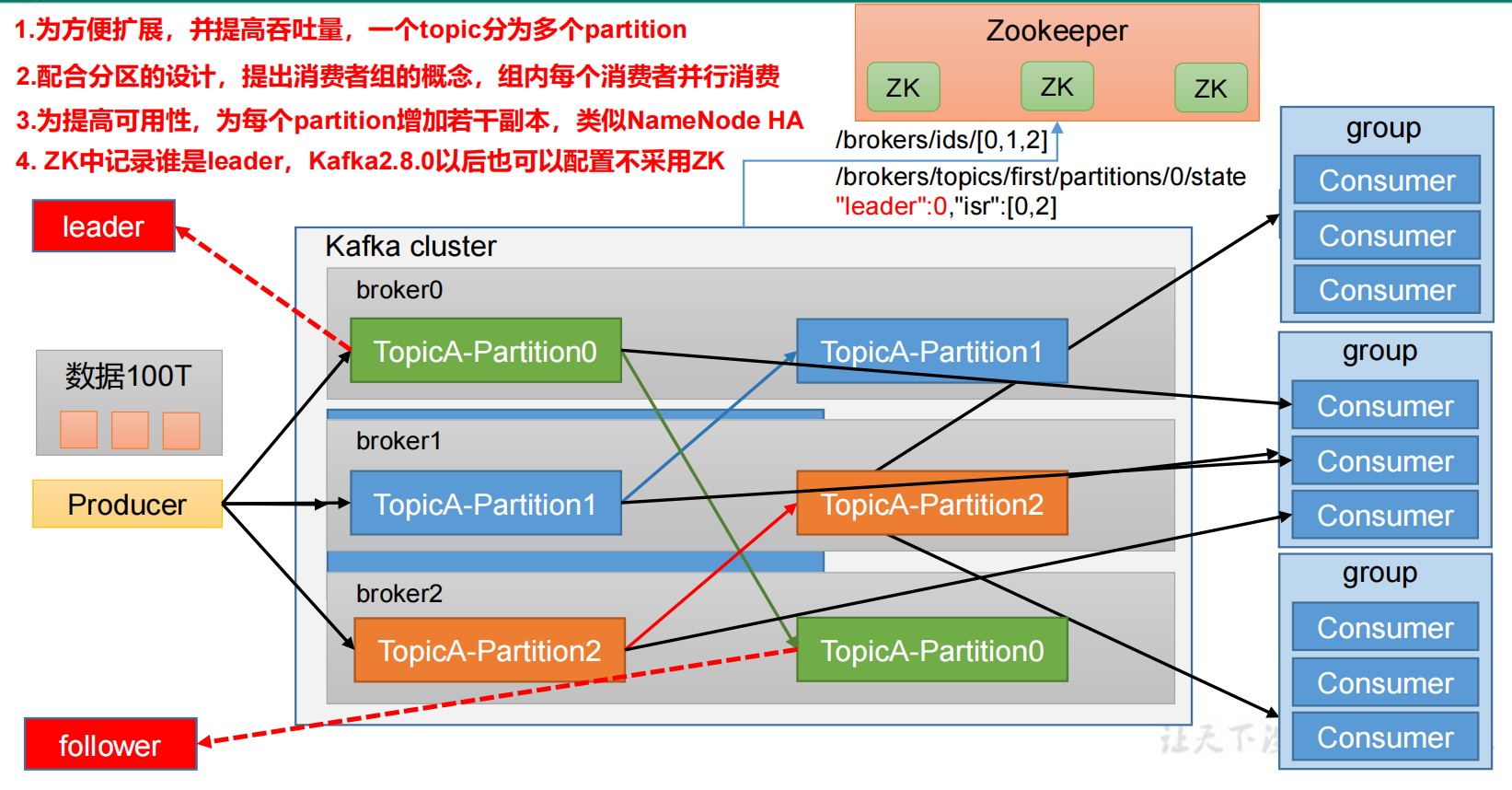
4、概念
(1)broker
即 kafka 节点
一个Kafka的集群通常由多个broker组成,这样才能实现负载均衡、以及容错
broker是无状态(Sateless)的,它们是通过ZooKeeper来维护集群状态
一个Kafka的broker每秒可以处理数十万次读写,每个broker都可以处理TB消息而不影响性能
(2)zookeeper
ZK用来管理和协调broker,并且存储了Kafka的元数据(例如:有多少topic、partition、consumer)
ZK服务主要用于通知生产者和消费者Kafka集群中有新的broker加入、或者Kafka集群中出现故障的broker。
PS:Kafka正在逐步想办法将ZooKeeper剥离,维护两套集群成本较高,社区提出KIP-500就是要替换掉ZooKeeper的依赖。“Kafka on Kafka”——Kafka自己来管理自己的元数据
(3)consumer group(消费者组)
消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
一个分区只能被一个组的某一个消费者消费,其他组的也可以同时消费
案例:存在一个主题有两个分区,两个消费者的情况下,发送100条消息
两个消费者属于同一个消费者组,两个消费者分别消费两个分区的数据,分别50次,总计100次,不重复
两个消费者不属于同一个消费者组,两个消费者都消费了100条消息,总计消费200次,即不同消费者组可重复消费消息
(4)Partition分区
分区,为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
默认一个topic有一个分区(partition),自己可设置多个分区(分区分散存储在服务器不同节点上)解决了一个海量数据如何存储的问题
例如:有2T的数据,一台服务器有1T,一个topic可以分多个区,分别存储在多台服务器上,解决海量数据存储问题。
(5)Replica副本
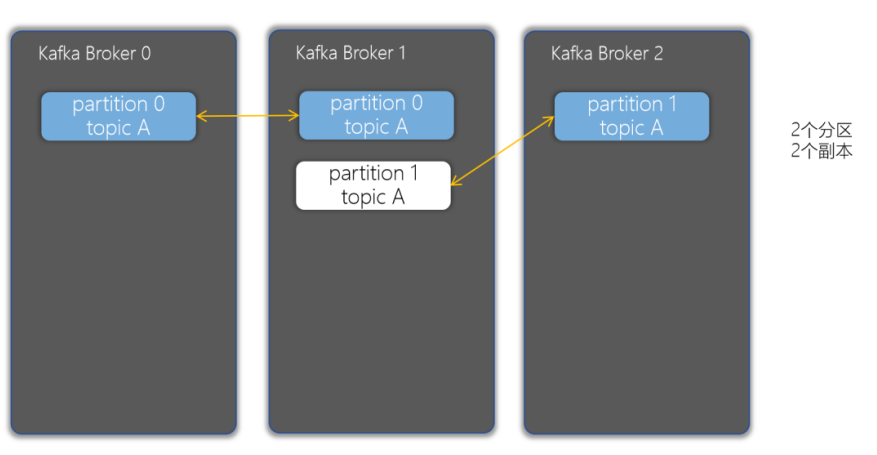
副本。一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个Follower。
- 副本可以确保某个服务器出现故障时,确保数据依然可用
- 在Kafka中,一般都会设计副本的个数>1
Leader 和Follower
Leader(主副本):每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 Leader。
Follower(备份副本):每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和Leader 数据的同步。Leader 发生故障时,某个 Follower 会成为新的 Leader。
(6)topic主题
主题是一个逻辑概念,用于生产者发布数据,消费者拉取数据
Kafka中的主题必须要有标识符,而且是唯一的,Kafka中可以有任意数量的主题,没有数量上的限制
在主题中的消息是有结构的,一般一个主题包含某一类消息
一旦生产者发送消息到主题中,这些消息就不能被更新(更改)
(7)offset偏移量
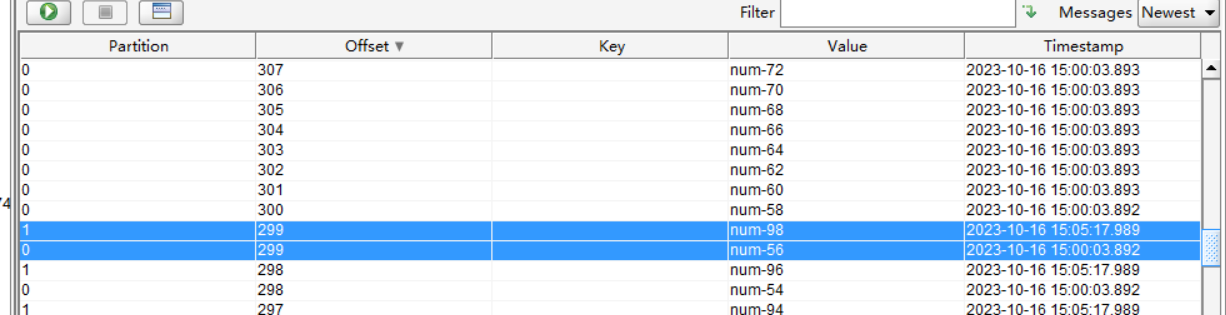
offset 是 Kafka 为每条消息分配的一个唯一的编号(同一主题同一分区中唯一),它表示消息在分区中的顺序位置。offset 是从 0 开始的,每当有新的消息写入分区时,offset 就会加 1。offset 是不可变的,即使消息被删除或过期,offset 也不会改变或重用。
在Kafka2.8版本前,Zookeeper的Consumer文件中存放消息被消费的记录(offset)
在Kafka2.8版本之后,消息被消费的记录(offset)存放在Kafka 的
_consumer_offsets主题中。在一个分区中,消息是有顺序的方式存储着,每个在分区的消费都是有一个递增的id。这个就是偏移量offset
偏移量在分区中才是有意义的。在分区之间,offset是没有任何意义的
offset 的作用主要有两个:
- 一是用来定位消息。通过指定 offset,消费者可以准确地找到分区中的某条消息,或者从某个位置开始消费消息。
- 二是用来记录消费进度。消费者在消费完一条消息后,需要提交 offset 来告诉 Kafka broker 自己消费到哪里了。这样,如果消费者发生故障或重启,它可以根据保存的 offset 来恢复消费状态。
二、Kafka安装
官网安装教程:https://kafka.apache.org/quickstart
下载:https://kafka.apache.org/downloads
1、配置文件
tar -xzf kafka_2.12-3.0.0.tgz解压后,编辑配置文件 ./kafka/config/server.properties
#broker 的全局唯一编号,不能重复,只能是数字。
broker.id=0
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘 IO 的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔
# /tmp/ 是 Linux 临时目录,所以必须修改为其他目录
log.dirs=/tmp/kafka-logs
#topic 在当前 broker 上的分区个数
num.partitions=1
#用来恢复和清理 data 下数据的线程数量
num.recovery.threads.per.data.dir=1
# 每个 topic 创建时的副本数,默认时 1 个副本
offsets.topic.replication.factor=1
#segment 文件保留的最长时间,超时将被删除
log.retention.hours=168
#每个 segment 文件的大小,默认最大 1G
log.segment.bytes=1073741824
# 检查过期数据的时间,默认 5 分钟检查一次是否数据过期
log.retention.check.interval.ms=300000
#配置连接 Zookeeper 集群地址(在 zk 根目录下创建/kafka,方便管理)
#zookeeper.connect=localhost:2181/kafka
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
# 需要修改为客户端可以访问的ip,否则java客户端无法连接
advertised.listeners=PLAINTEXT://外网ip:9092如果只是简单启动,只需要修改 broker.id 、log.dirs、 zookeeper.connect
- broker.id 不得重复,整个集群中唯一
后续新增节点,只需加入 Zookeeper 集群即可
kafka 默认启动端口 9092
2、ZK方式启动
ZK启动
nohup bin/zookeeper-server-start.sh config/zookeeper.properties 2>$1 &Kafka 启动
bin/kafka-server-start.sh config/server.properties3、KRaft方式启动
生成集群UUID
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"格式化日志目录
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties启动 Kafka
bin/kafka-server-start.sh config/kraft/server.properties4、脚本统一启动关闭
为了方便将来进行一键启动、关闭Kafka,我们可以编写一个shell脚本来操作。将来只要执行一次该脚本就可以快速启动/关闭Kafka。
配置KAFKA_HOME环境变量
vim /etc/profile
export KAFKA_HOME=/export/server/kafka_2.12-2.4.1
export PATH=:$PATH:${KAFKA_HOME}
#源文件无下面这条需手动添加
export PATH
#每个节点加载环境变量
source /etc/profile准备slave配置文件,用于保存要启动哪几个节点上的kafka
10.211.55.8
10.211.55.9
10.211.55.7编写 start-kafka.sh 脚本
#!/bin/bash
cat /export/onekey/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;export JMX_PORT=9988;nohup ${KAFKA_HOME}/bin/kafka-server-start.sh ${KAFKA_HOME}/config/server.properties >/dev/nul* 2>&1 & "
wait
}&
done编写 stop-kafka.sh 脚本
#!/bin/bash
cat /export/onekey/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;jps |grep Kafka |cut -d' ' -f1 |xargs kill -s 9"
wait
}&
done给 start-kafka.sh、stop-kafka.sh 配置执行权限
chmod u+x start-kafka.sh
chmod u+x stop-kafka.sh执行shell脚本需实现服务期间ssh免密登录
5、kafka tool
kafka tool 工具下载地址
https://www.kafkatool.com/download.html
创建连接
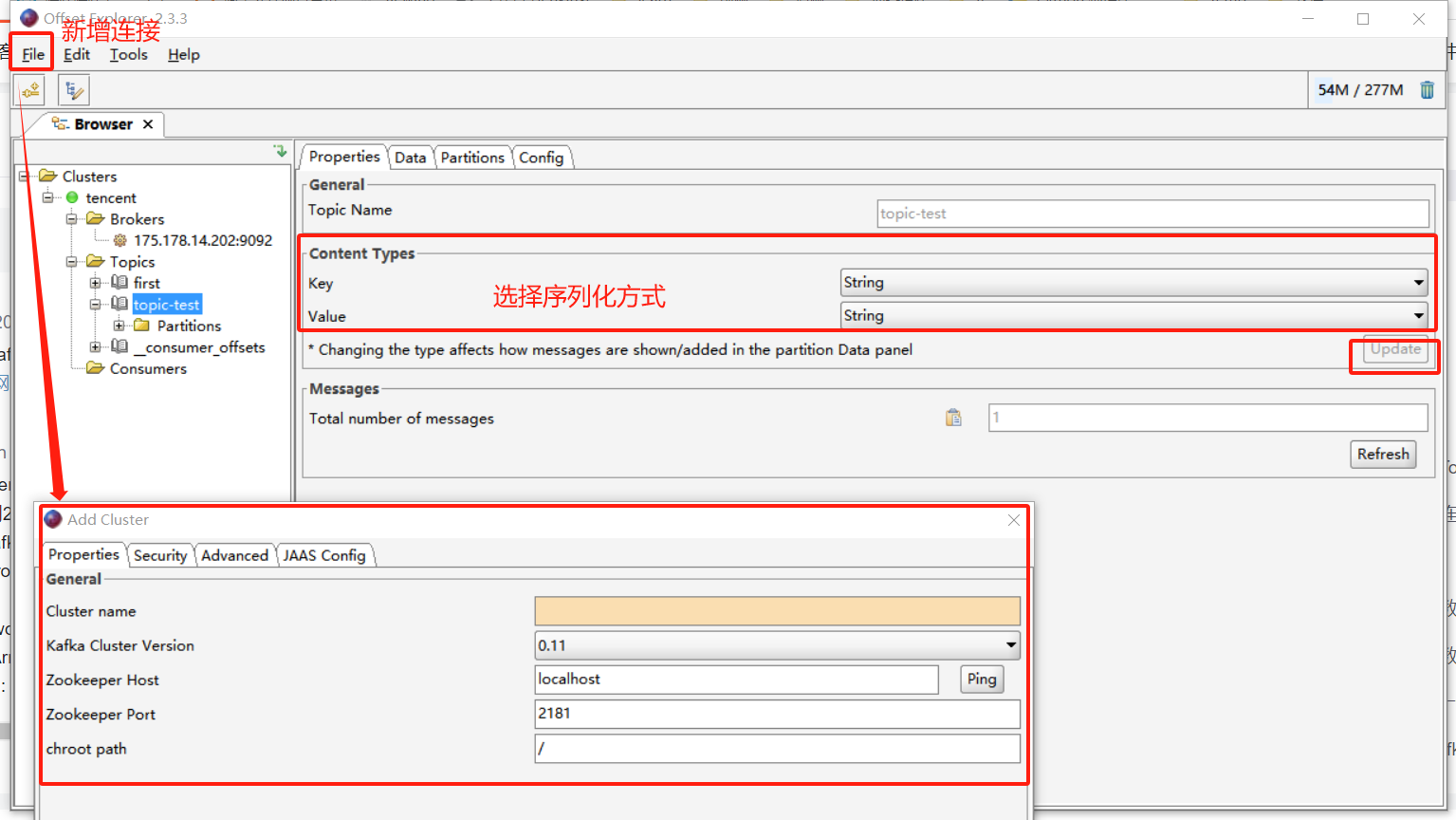
查看消息
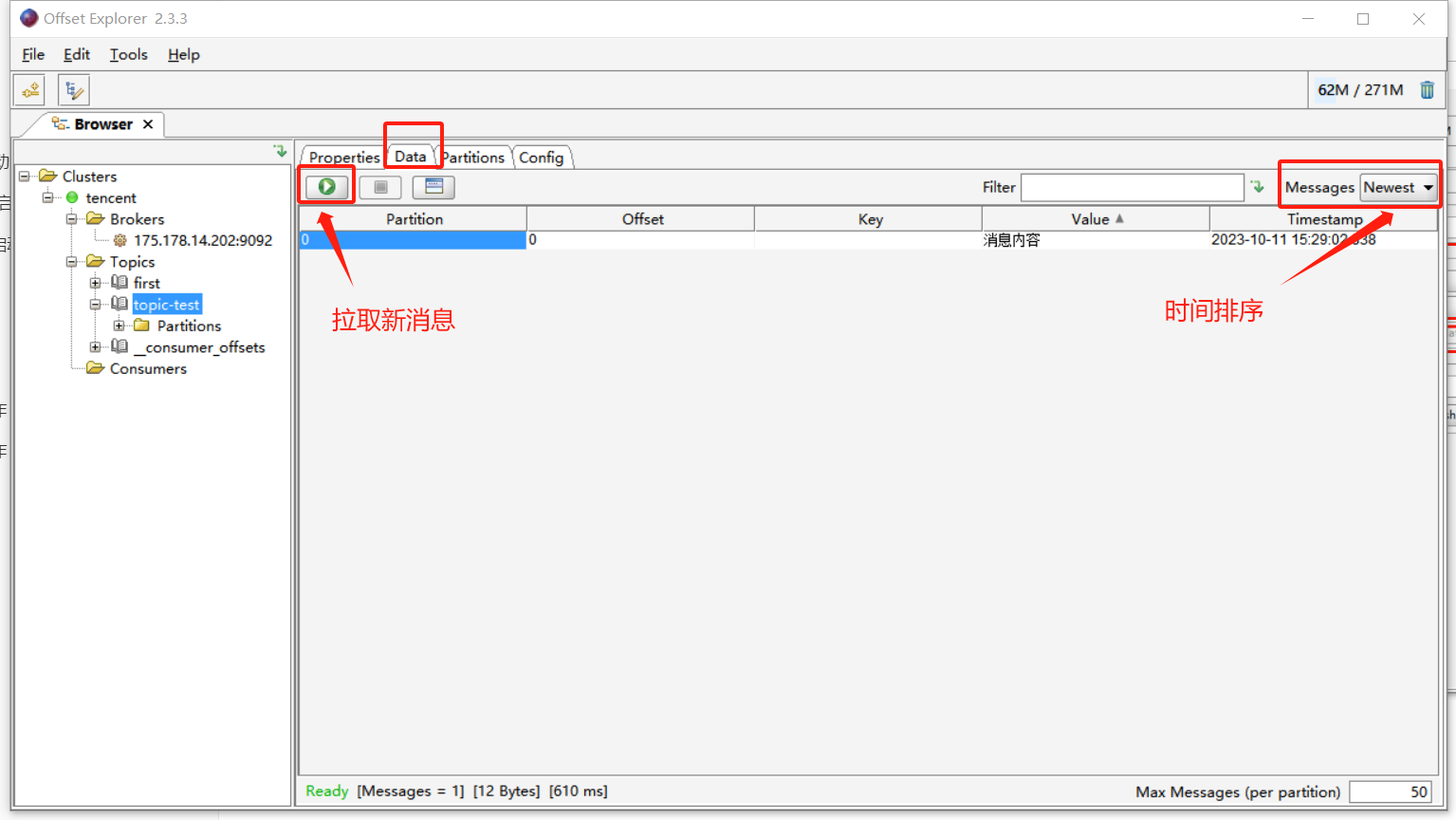
三、命令行操作
1、主题操作
(1)查看操作主题命令参数
bin/kafka-topics.sh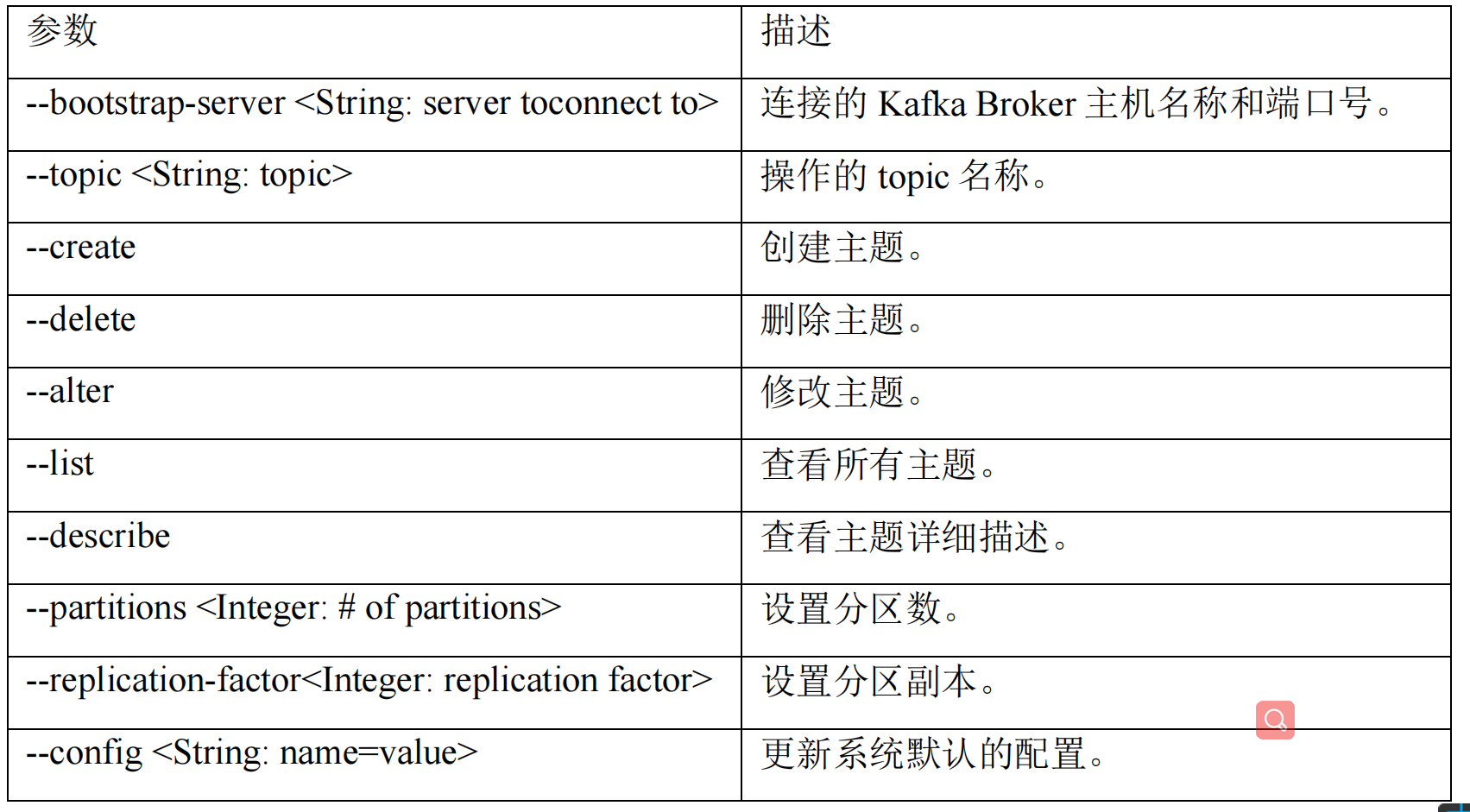
(2)查看当前服务器中的所有 topic
kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --list(3)创建 first topic
kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --create --partitions 1 --replication-factor 3 --topic first选项说明:
--topic定义 topic 名--replication-factor定义副本数--partitions定义分区数
(4)修改分区数
注意:分区数只能增加,不能减少
kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --alter --topic first --partitions 3(5)查看 first 主题的详情
kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --describe --topic first(6)删除 topic
kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --delete --topic first2、生产者操作
(1)连接kafka生产者
kafka-console-producer.sh --bootstrap-server 127.0.0.1:9092 --topic first参数 描述
--bootstrap-server <String: server toconnect to>连接的 Kafka Broker 主机名称和端口号。--topic <String: topic>操作的 topic 名称。
(2)发送消息
[atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh --
bootstrap-server 127.0.0.1:9092 --topic first
>hello world
>Hi HI3、消费者操作
(1)查看操作消费者命令参数
kafka-console-consumer.sh参数 描述
–bootstrap-server <String: server toconnect to>连接的 Kafka Broker 主机名称和端口号。–topic <String: topic>操作的 topic 名称。–from-beginning从头开始消费。–group <String: consumer group id>指定消费者组名称。
(2)消费 first 主题中的数据
kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic first阻塞等待生产者数据并消费,不会消费历史数据(即消费者启动之前生产者发送的数据)
(3)把主题中所有的数据读取出来
(包括历史数据)
kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --from-beginning --topic first四、Broker 原理
1、Broker设计
以下主题 TopicA 为 三节点、两分区、三副本的架构图
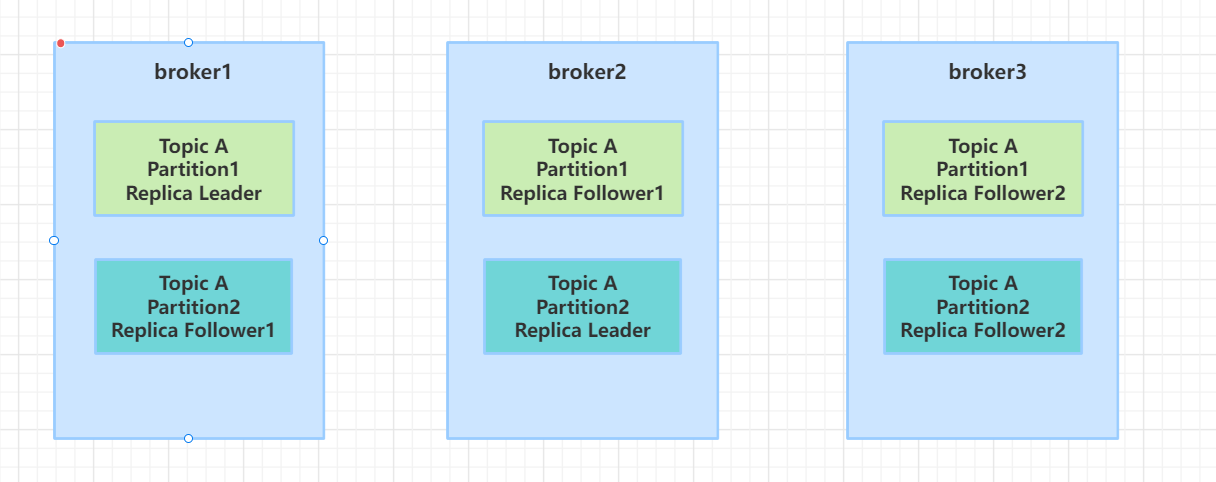
为了提高吞吐量,每个topic也会都多个分区,同时为了保持可靠性,每个分区还会有多个副本。这些分区副本被均匀的散落在每个broker上,其中每个分区副本中有一个副本为leader,其他的为follower。
2、Zookeeper
(1)ZK作用
Zookeeper在Kafka中扮演了重要的角色,kafka使用zookeeper进行元数据管理,保存broker注册信息,包括主题(Topic)、分区(Partition)信息等,选择分区leader。
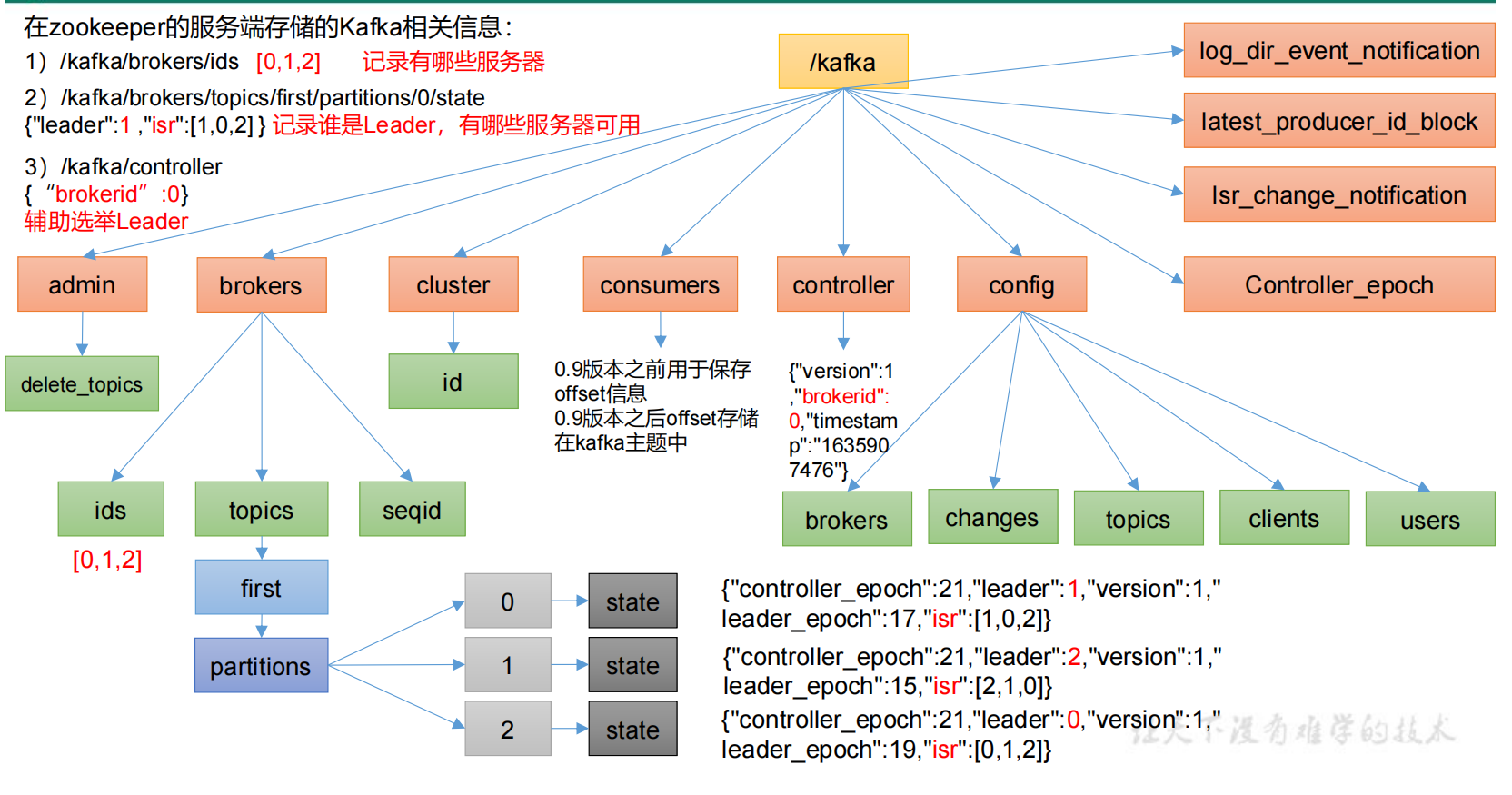
(2)Broker选举Leader
这里需要先明确一个概念leader选举,因为kafka中涉及多处选举机制,容易搞混,Kafka由三个方面会涉及到选举:
- broker(控制器)选leader
- 分区多副本选leader
- 消费者选Leader
在kafka集群中由很多的broker(也叫做控制器),但是他们之间需要选举出一个leader,其他的都是follower。broker的leader有很重要的作用,诸如:创建、删除主题、增加分区并分配leader分区;集群broker管理,包括新增、关闭和故障处理;分区重分配(auto.leader.rebalance.enable=true,后面会介绍),分区leader选举。
每个broker都有唯一的brokerId,他们在启动后会去竞争注册zookeeper上的Controller结点,谁先抢到,谁就是broker leader。而其他broker会监听该结点事件,以便后续leader下线后触发重新选举。
https://blog.csdn.net/weixin_46075832/article/details/126703474

